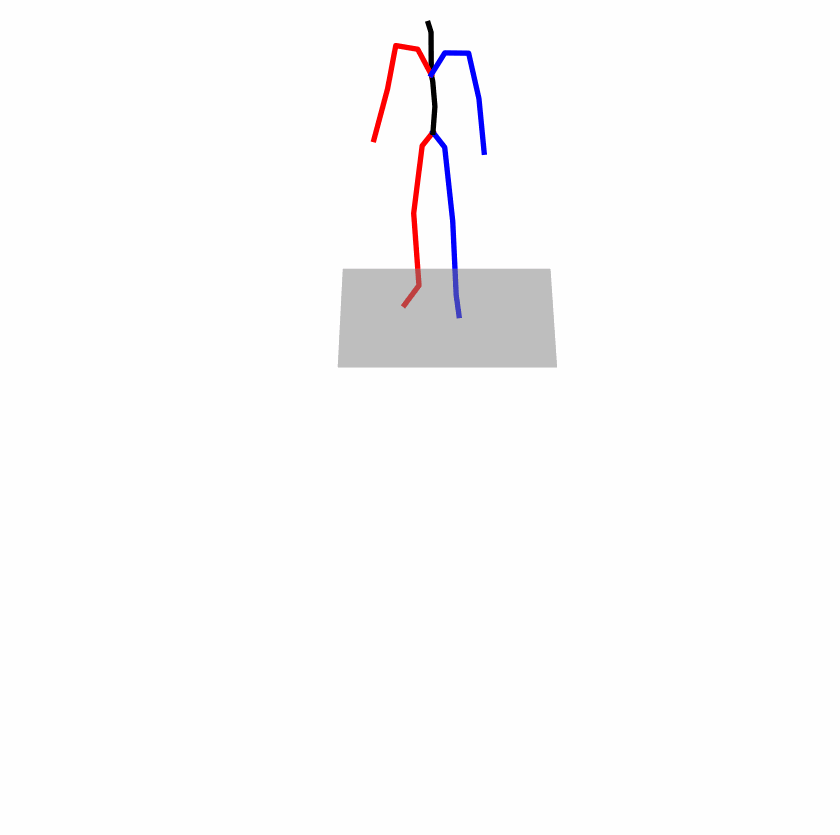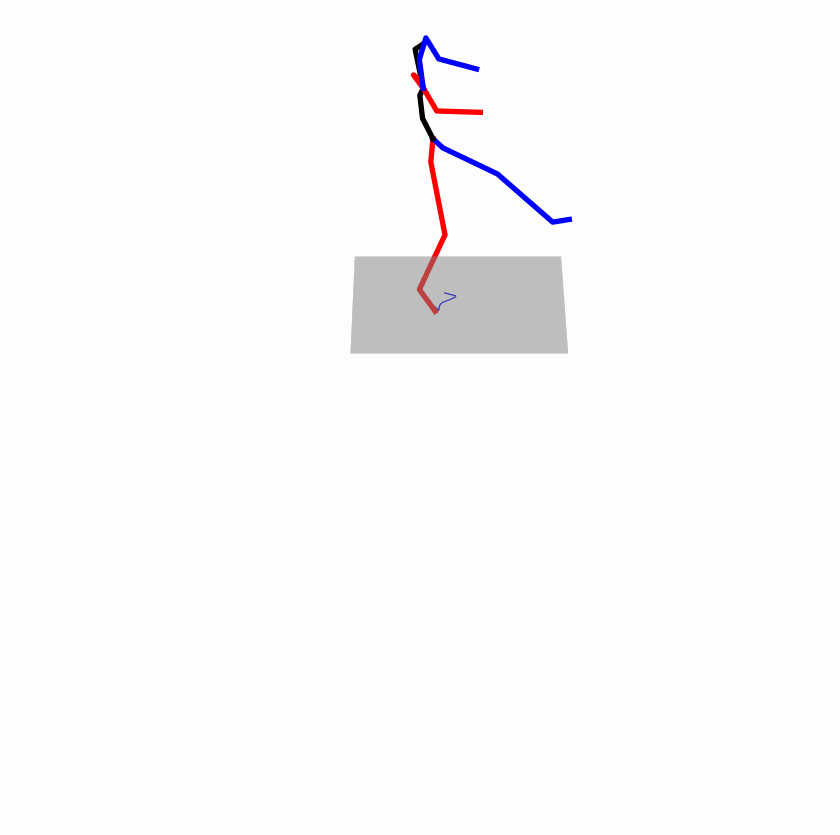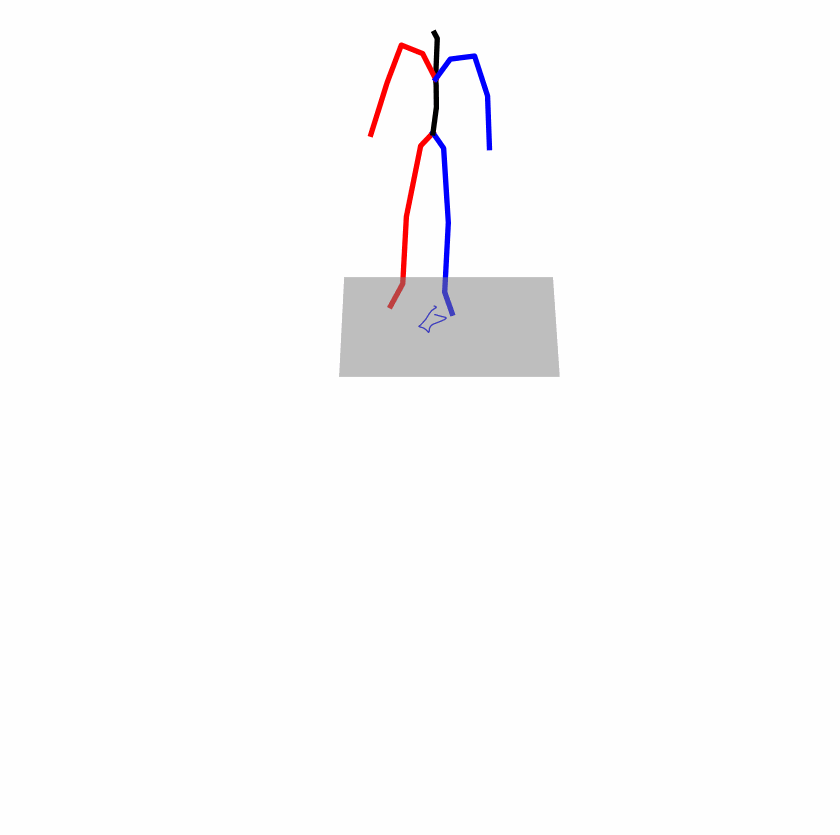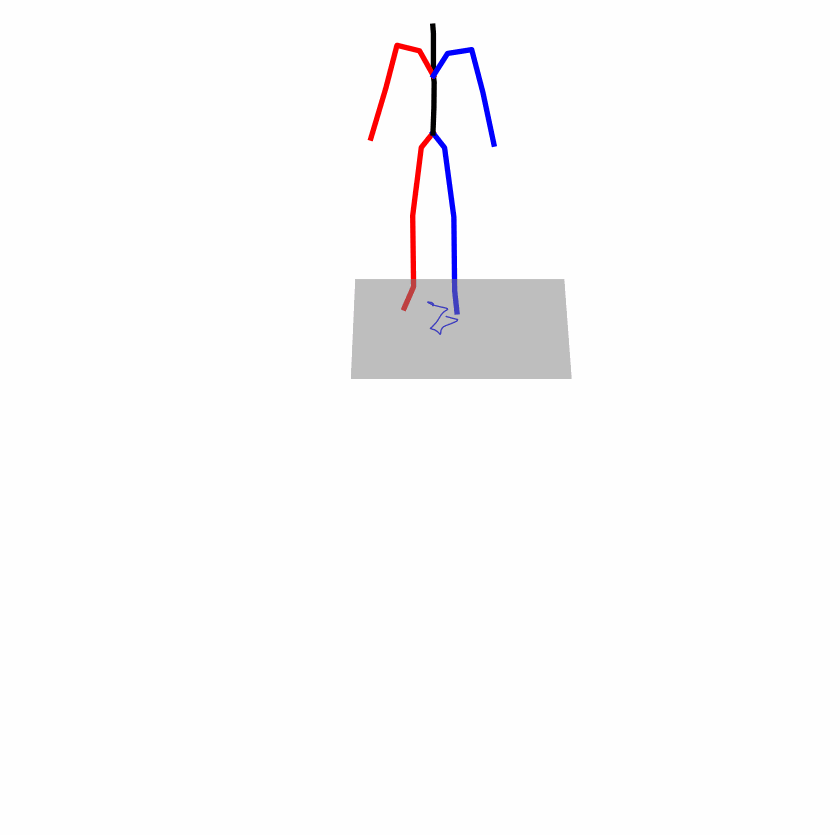
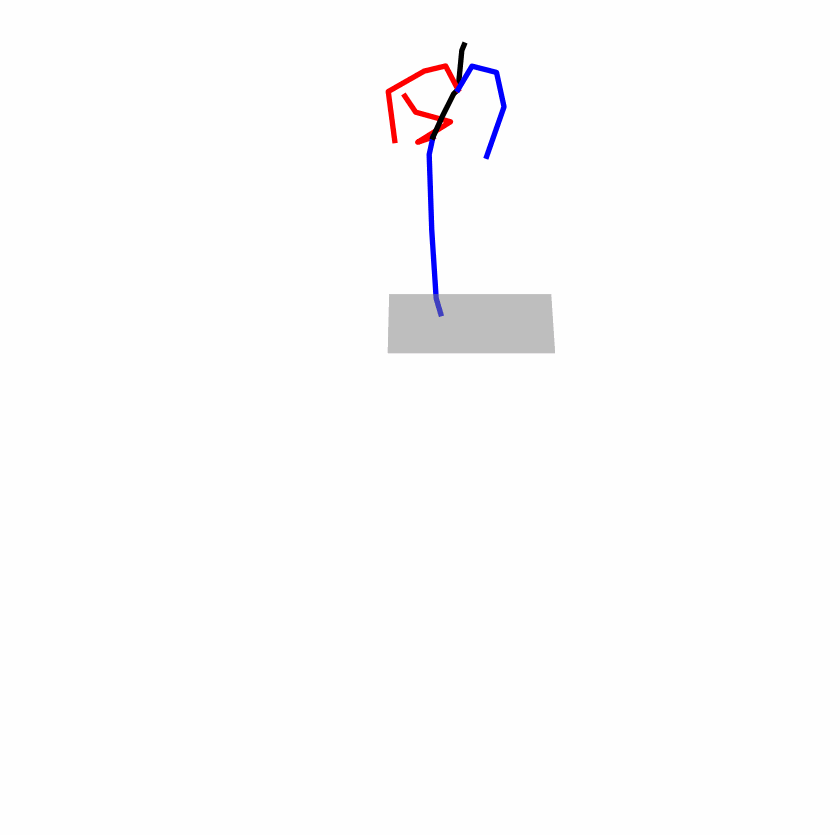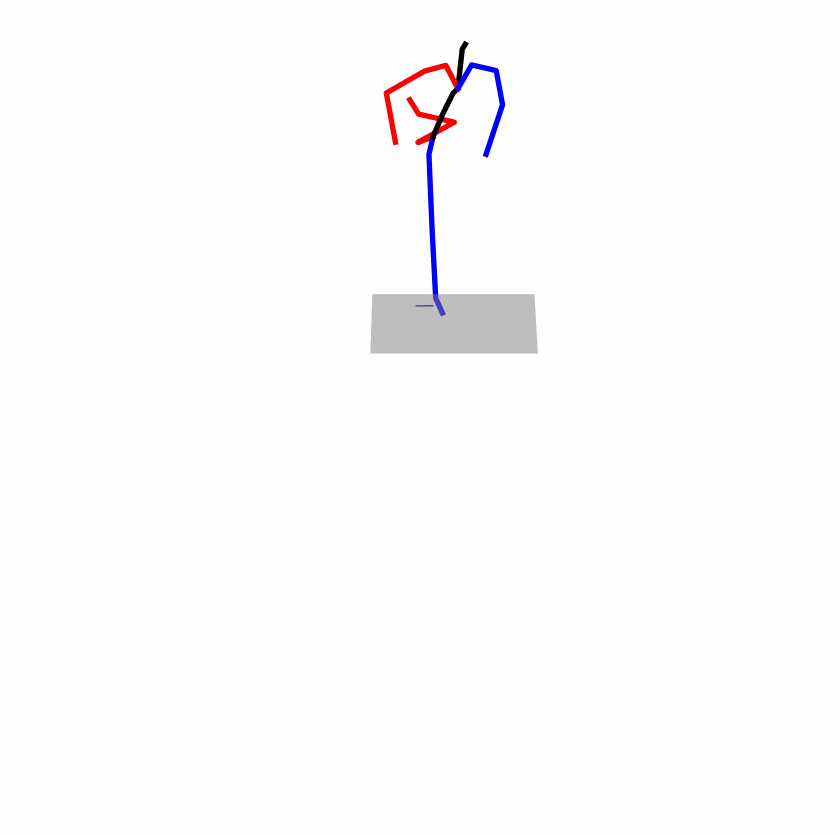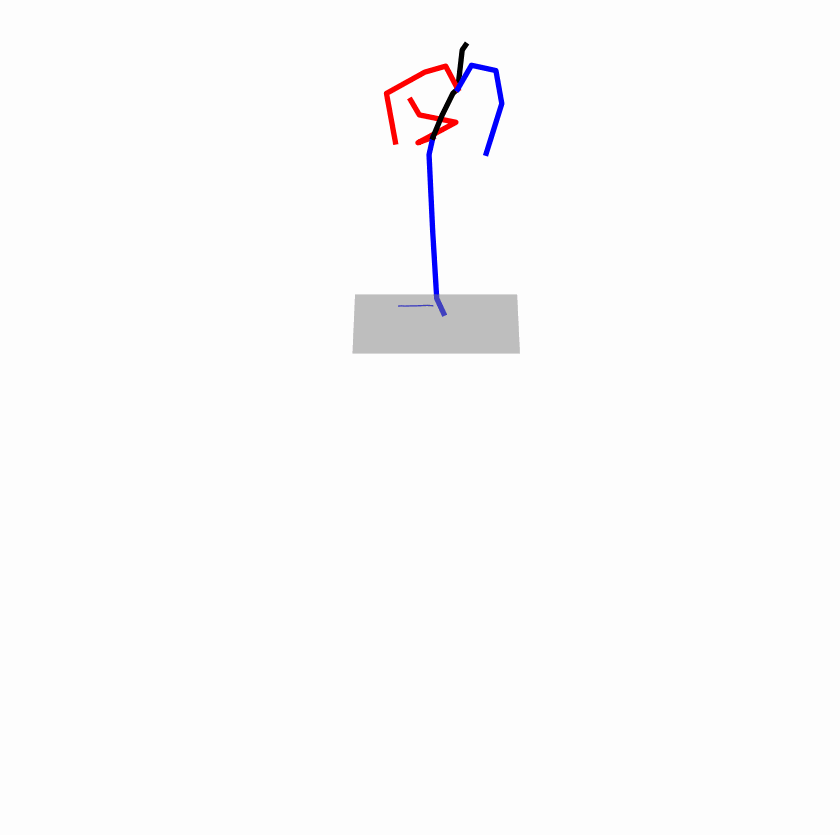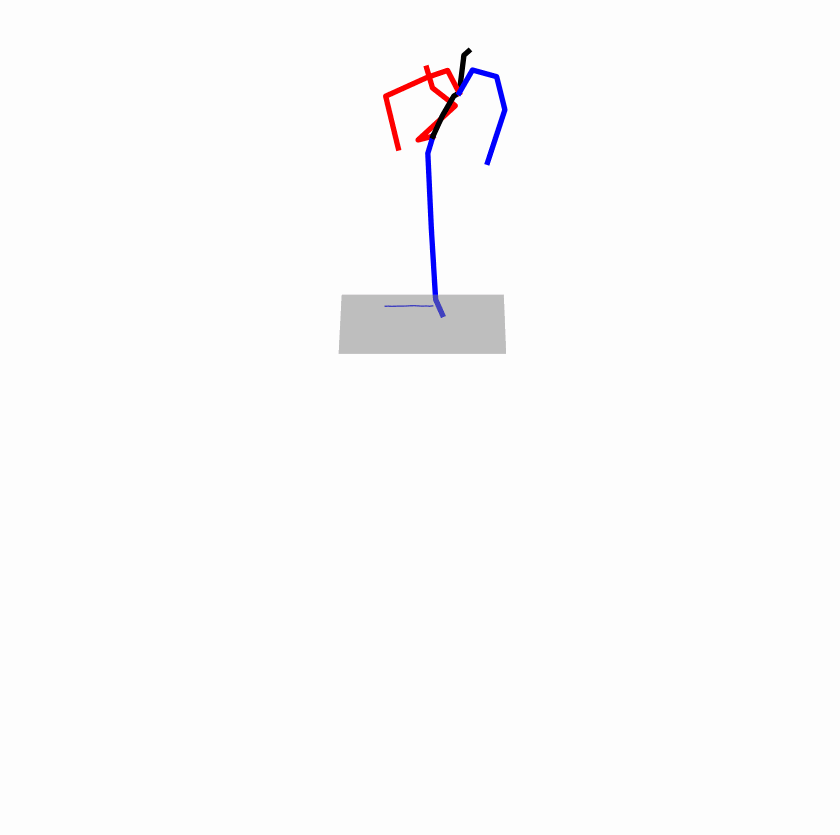
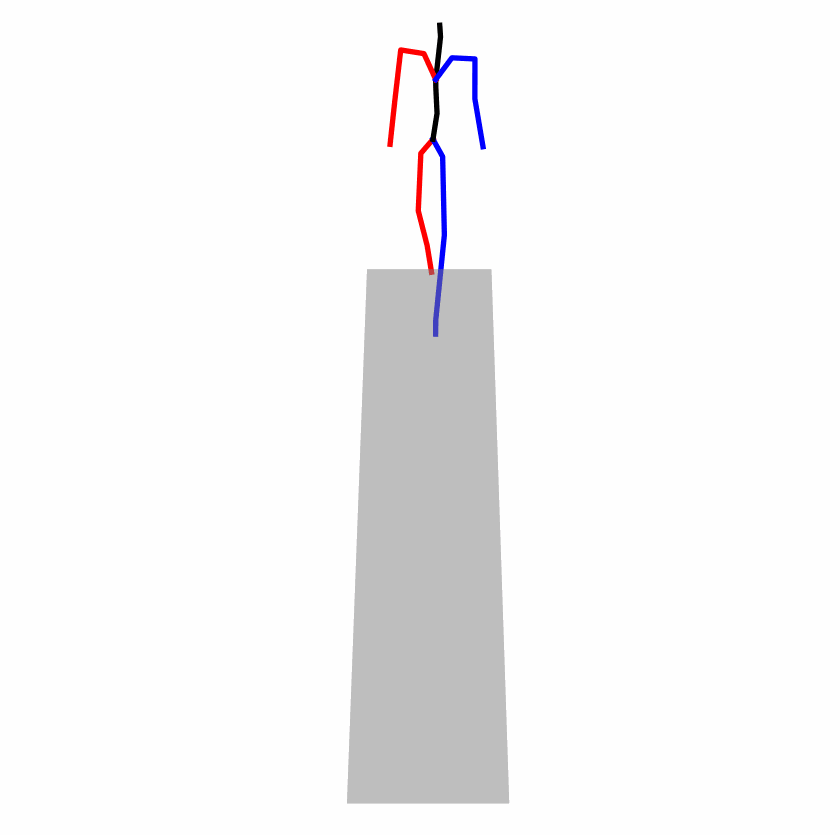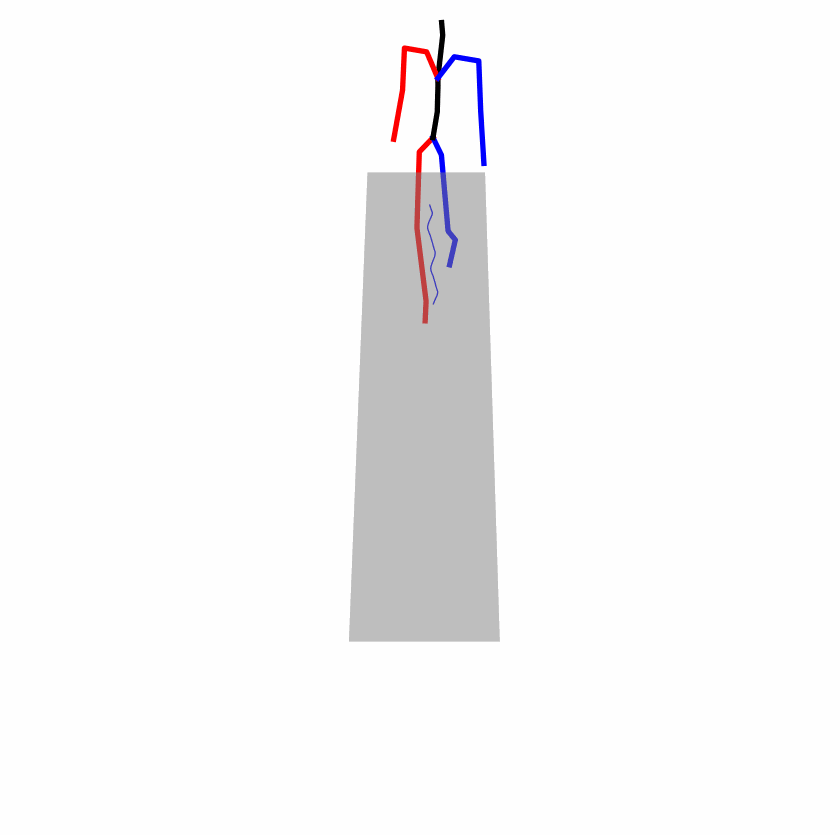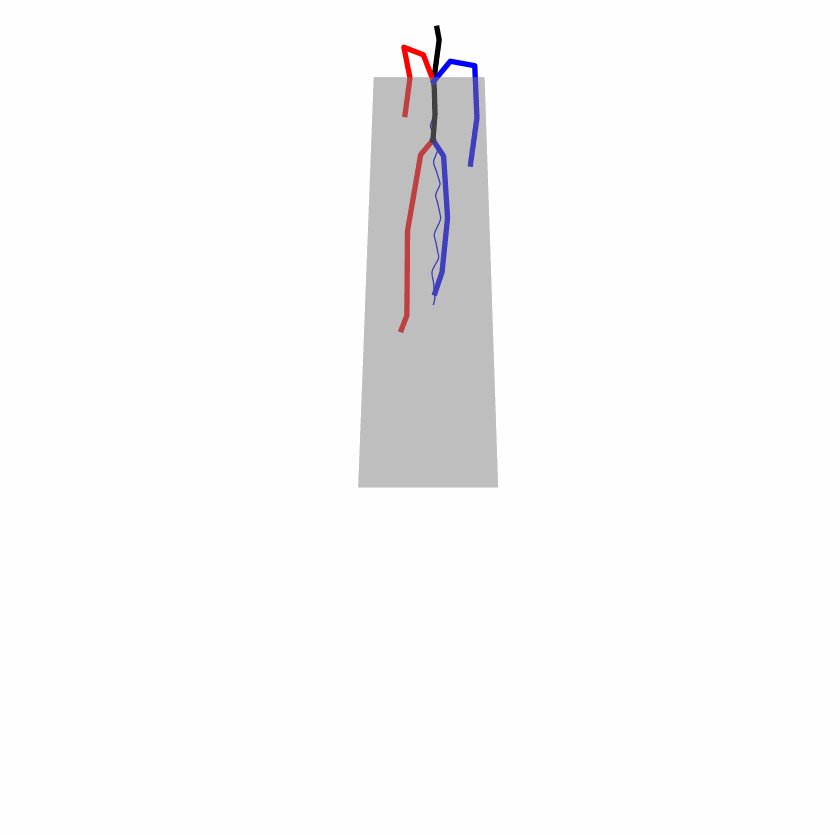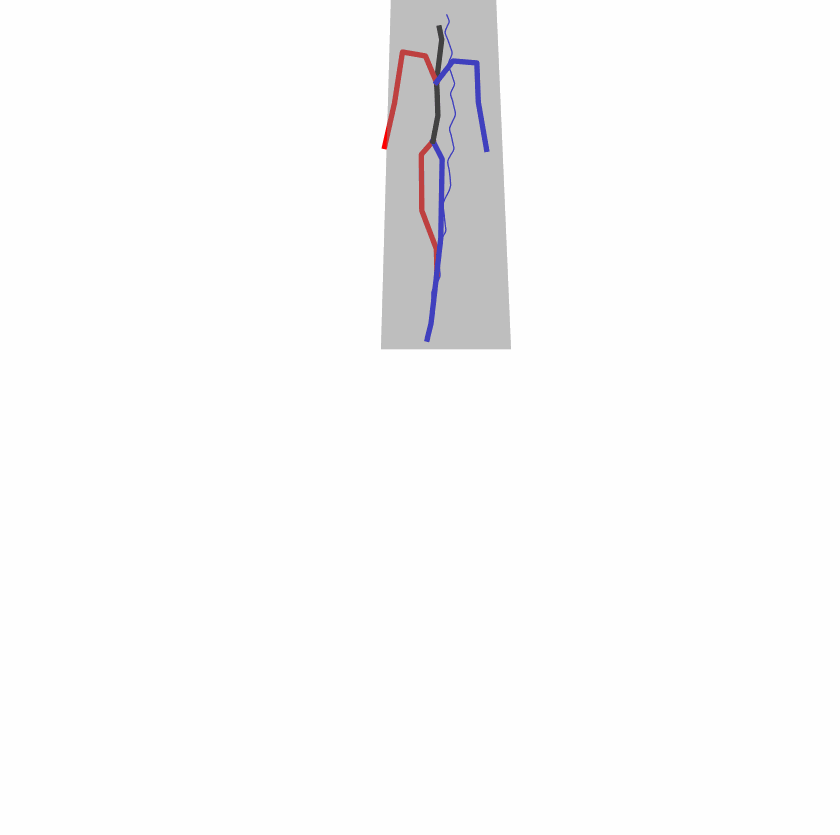
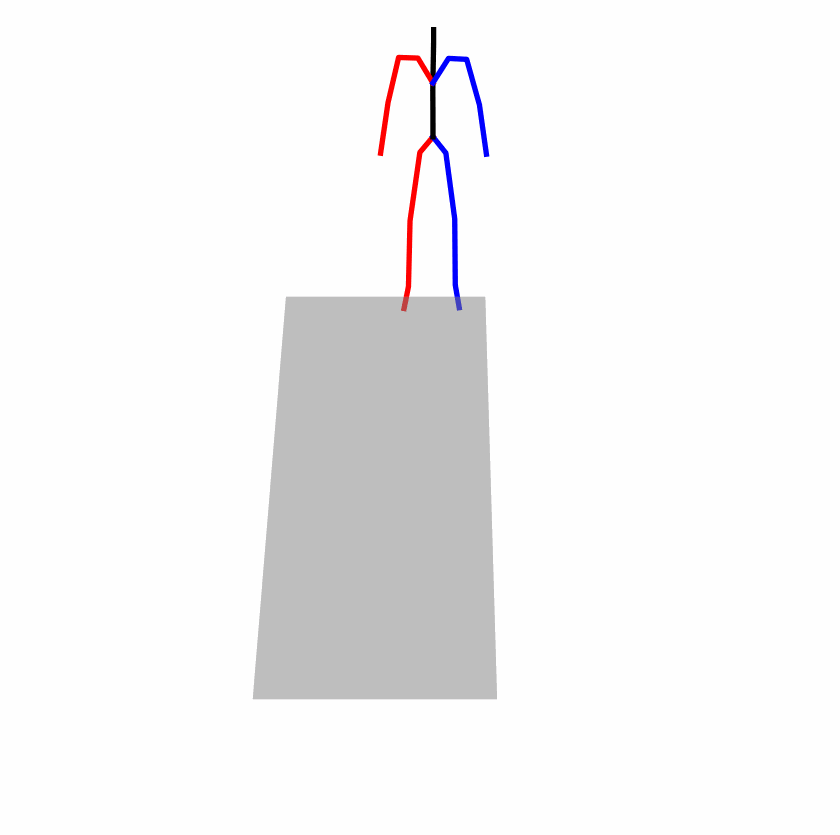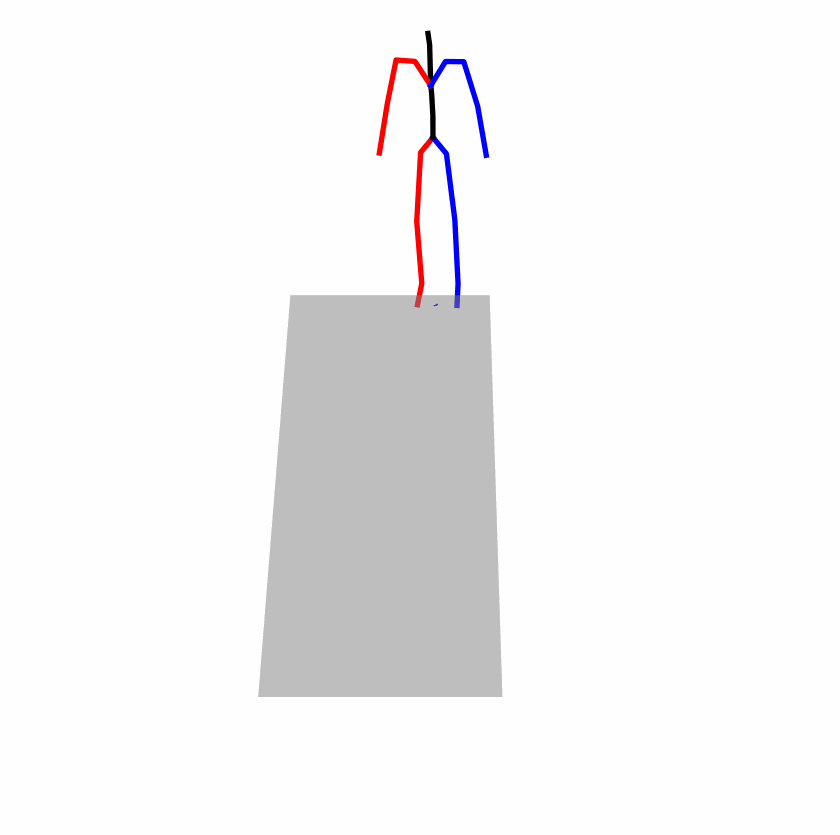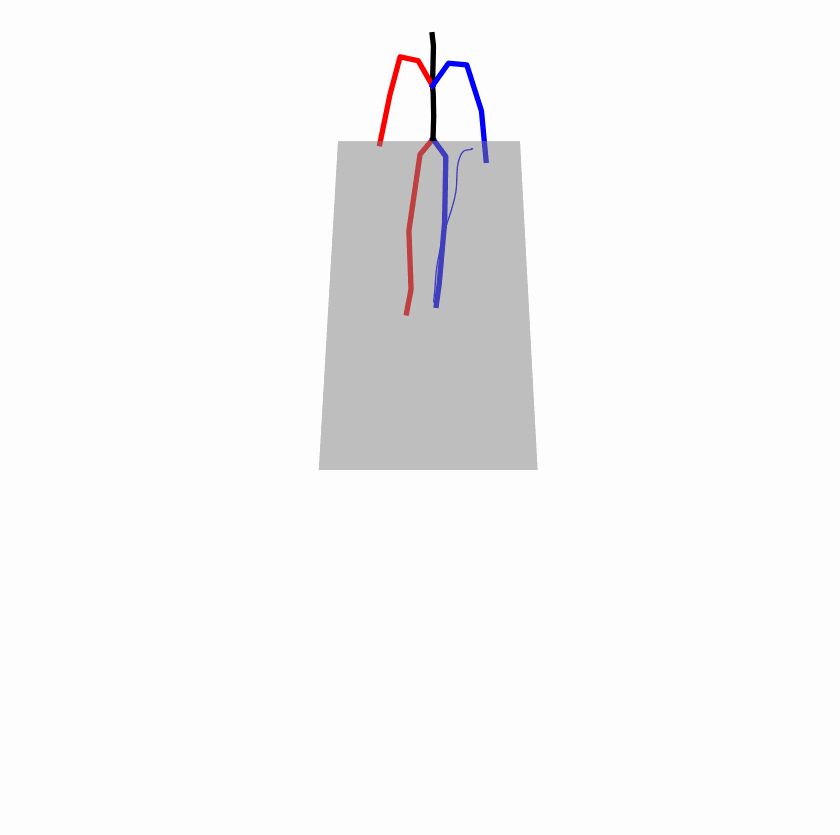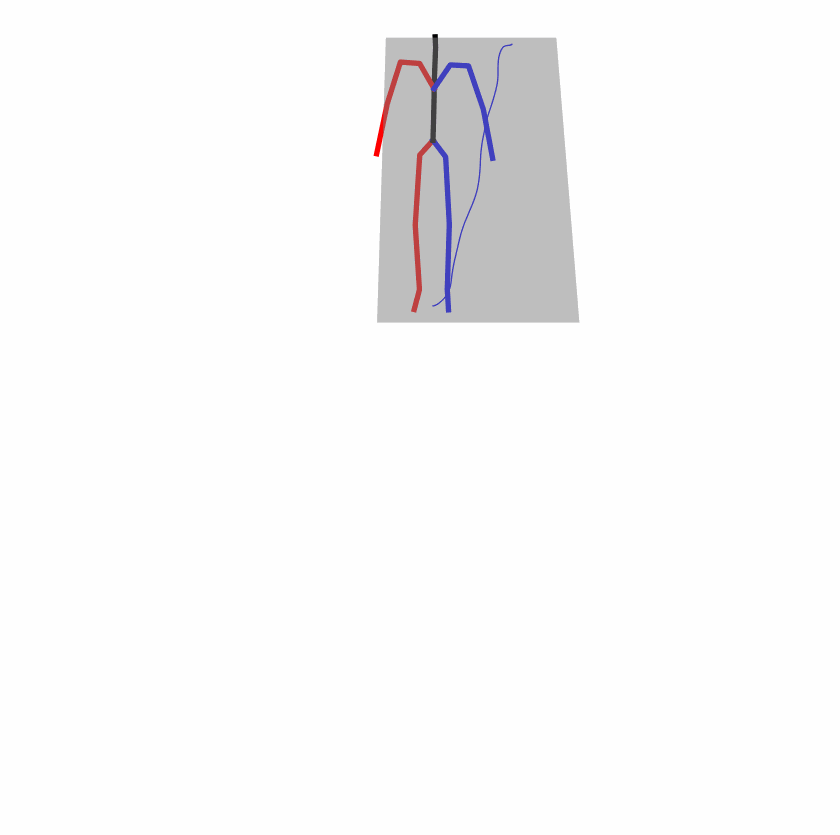
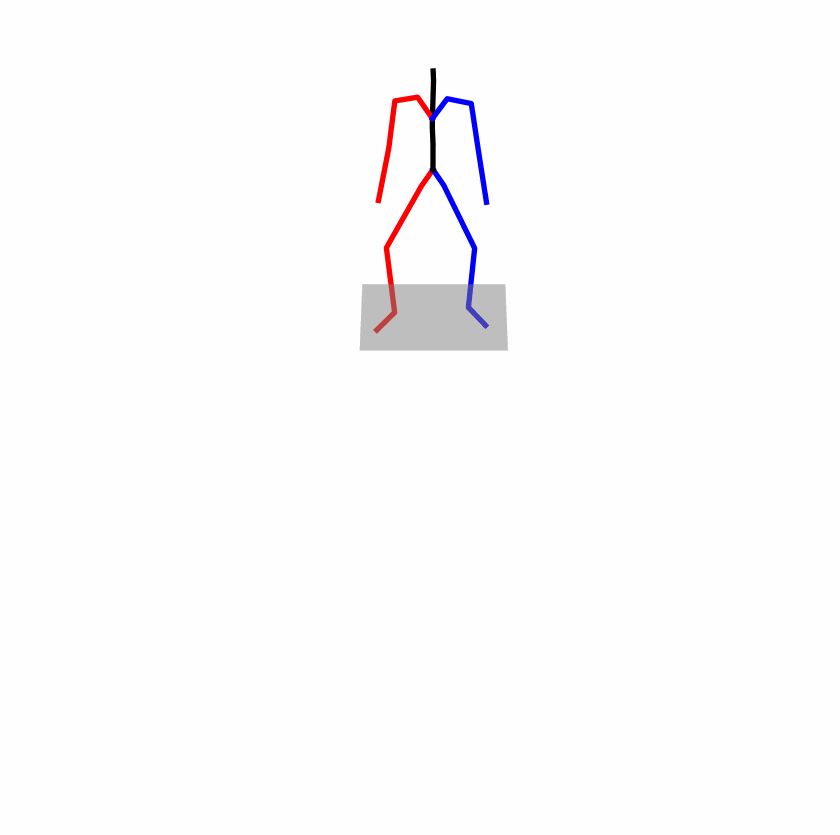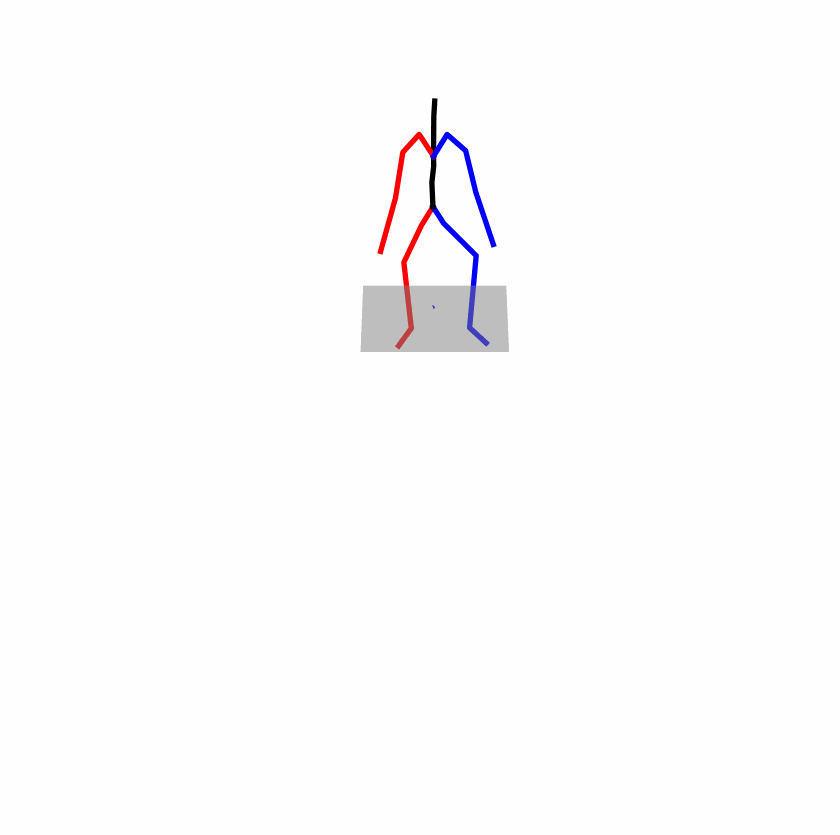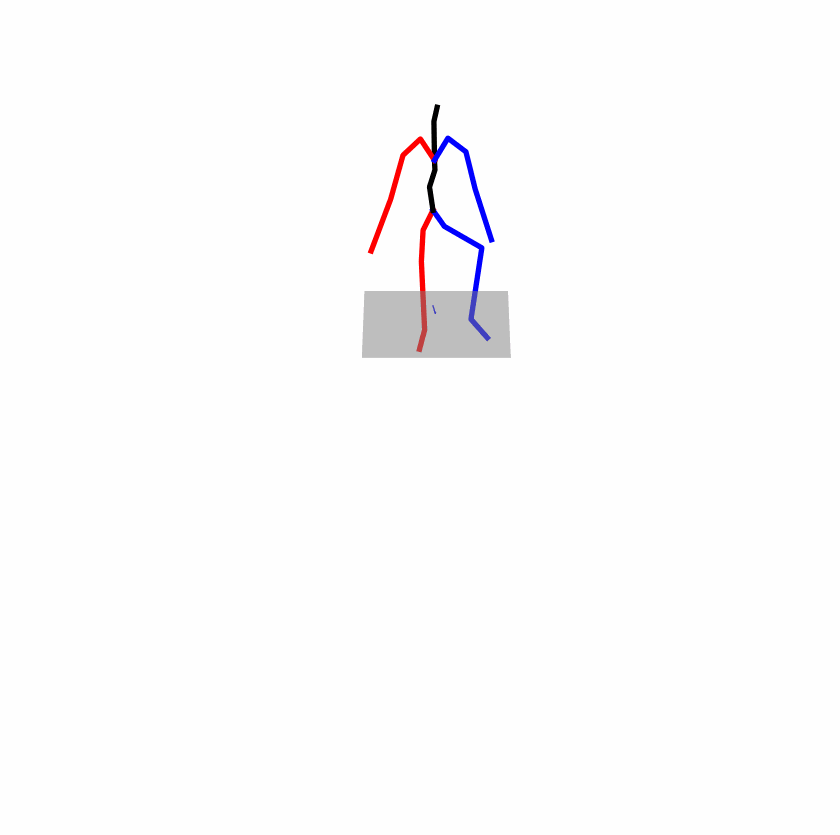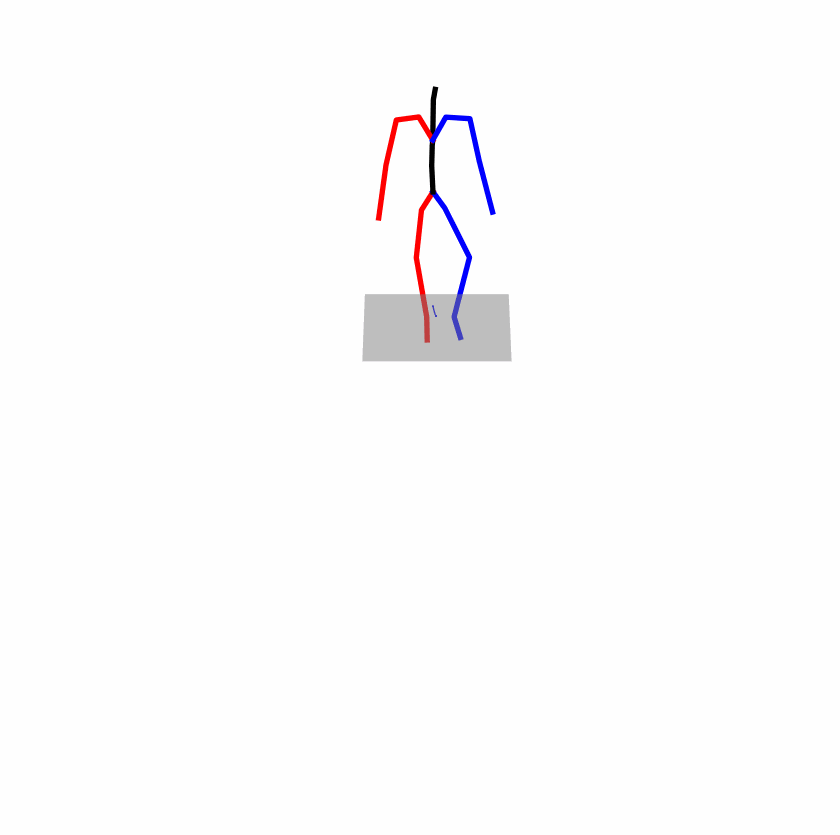
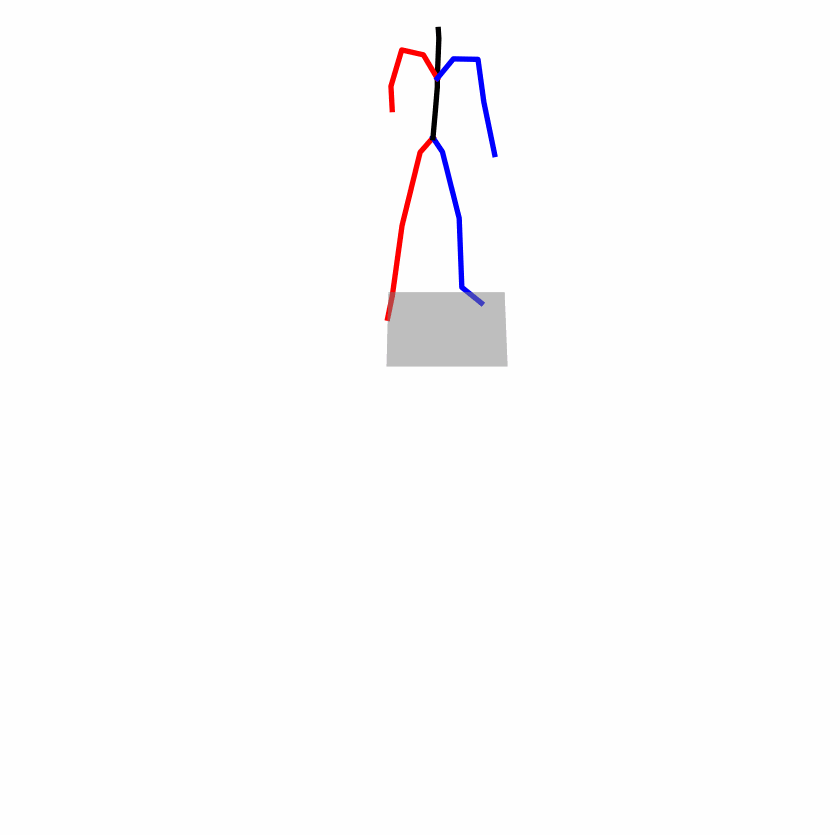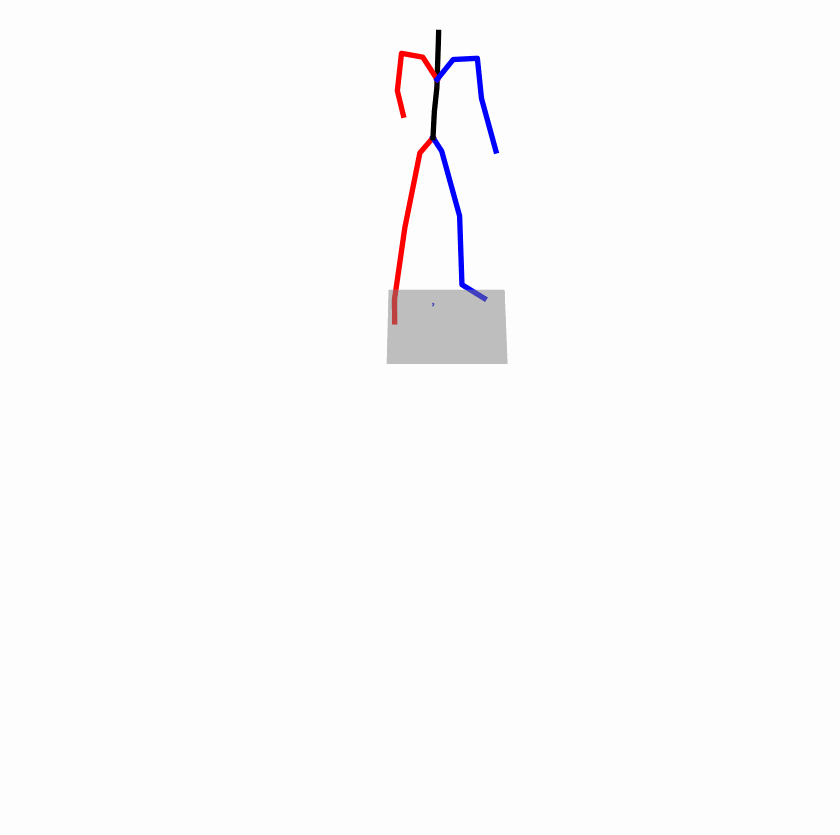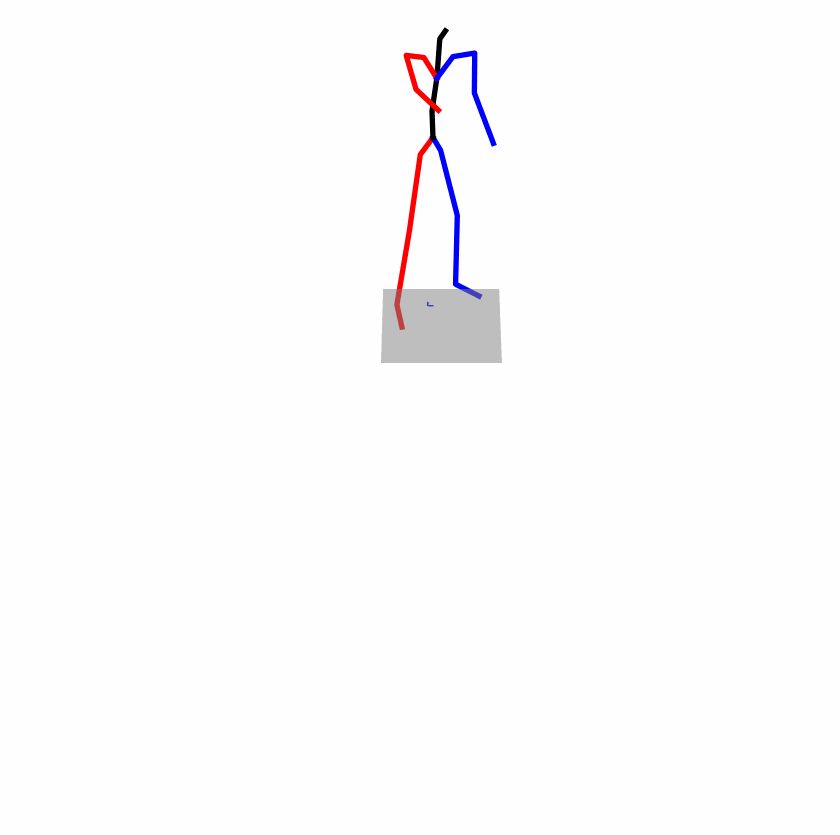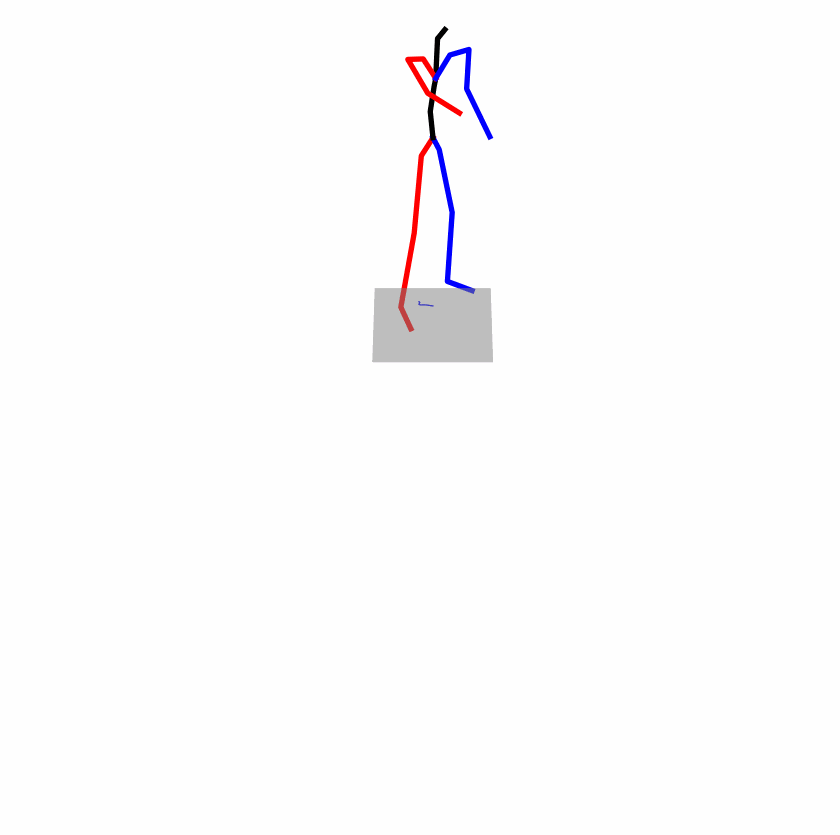
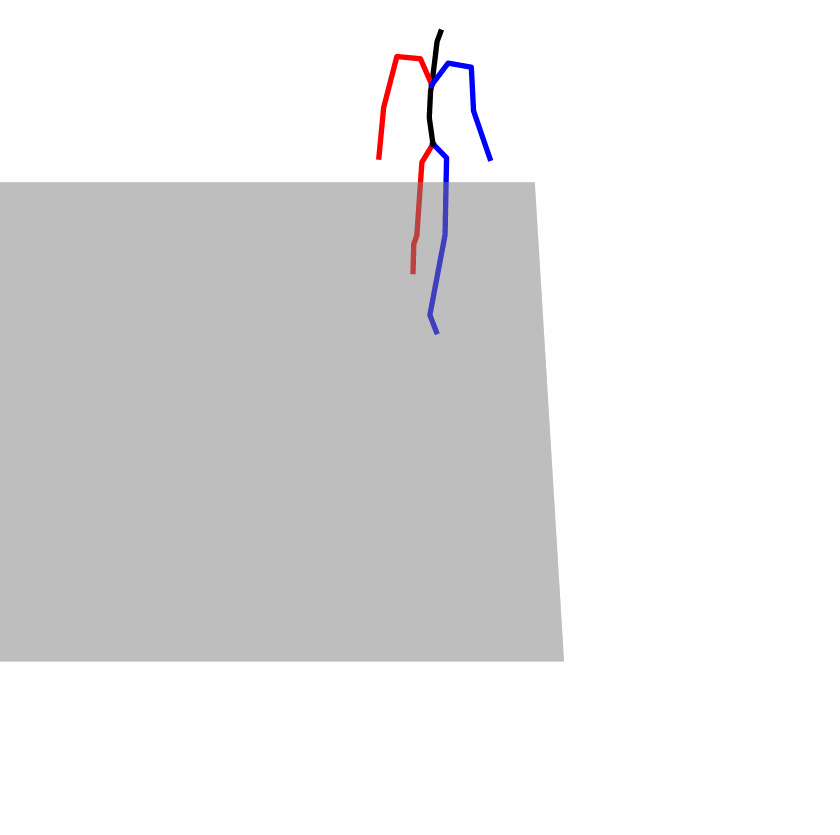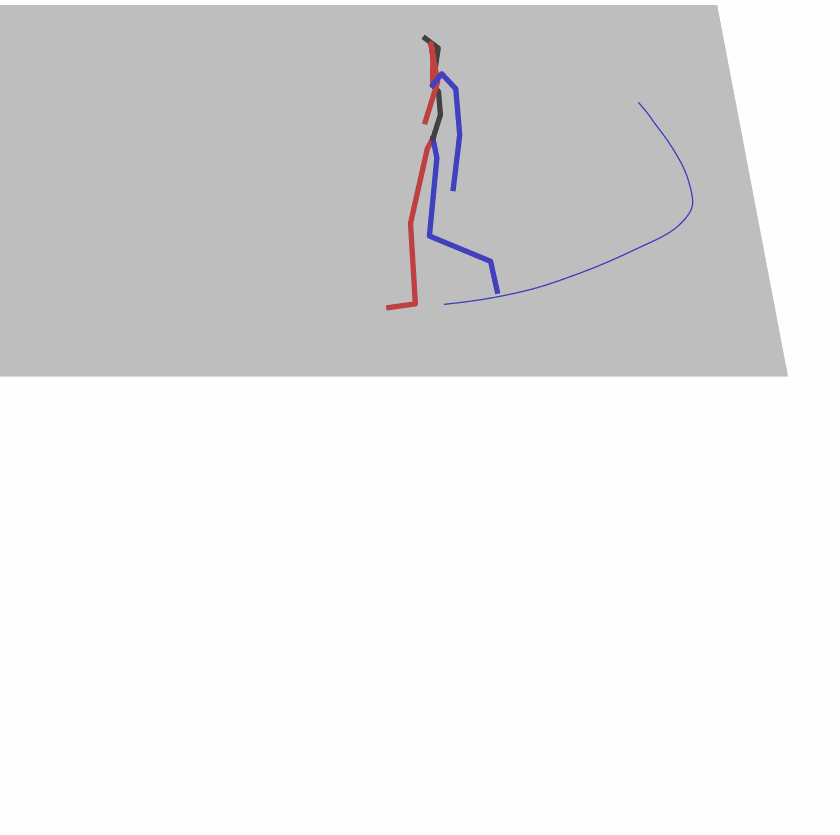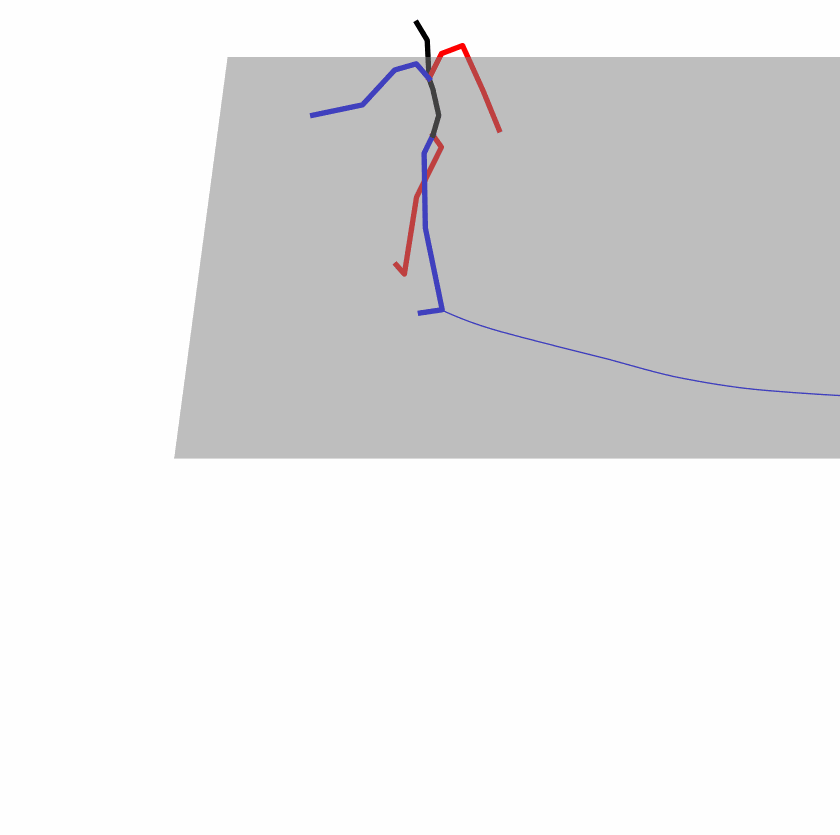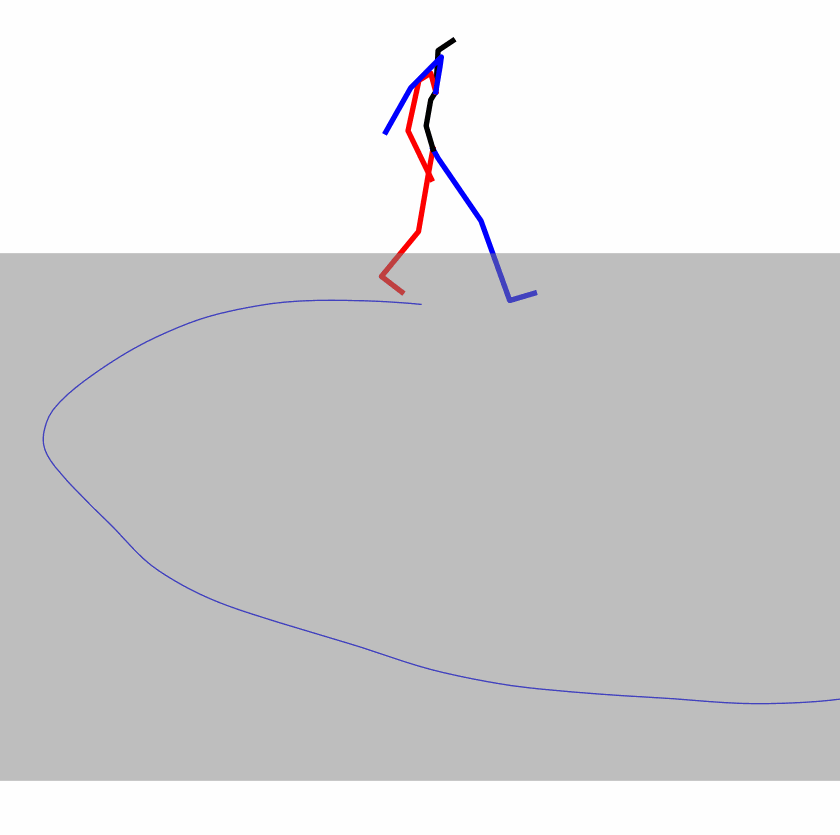
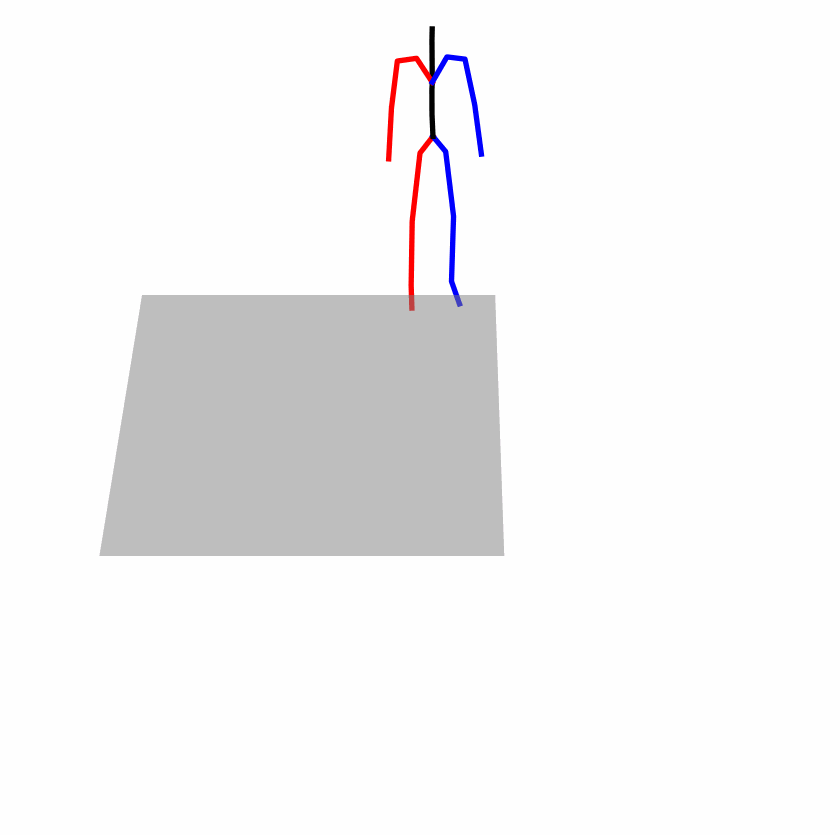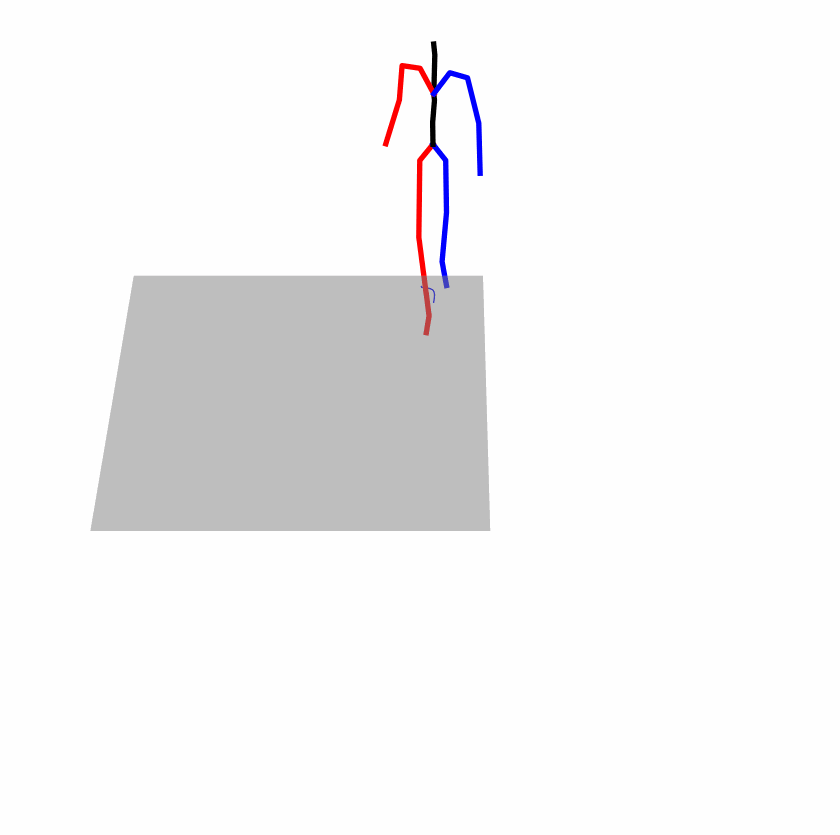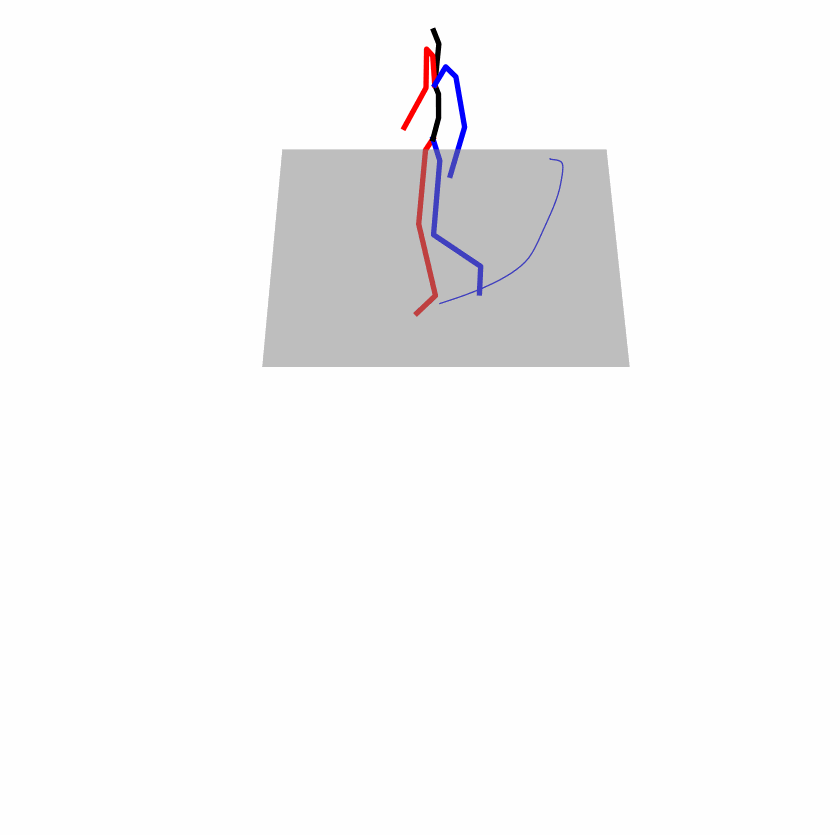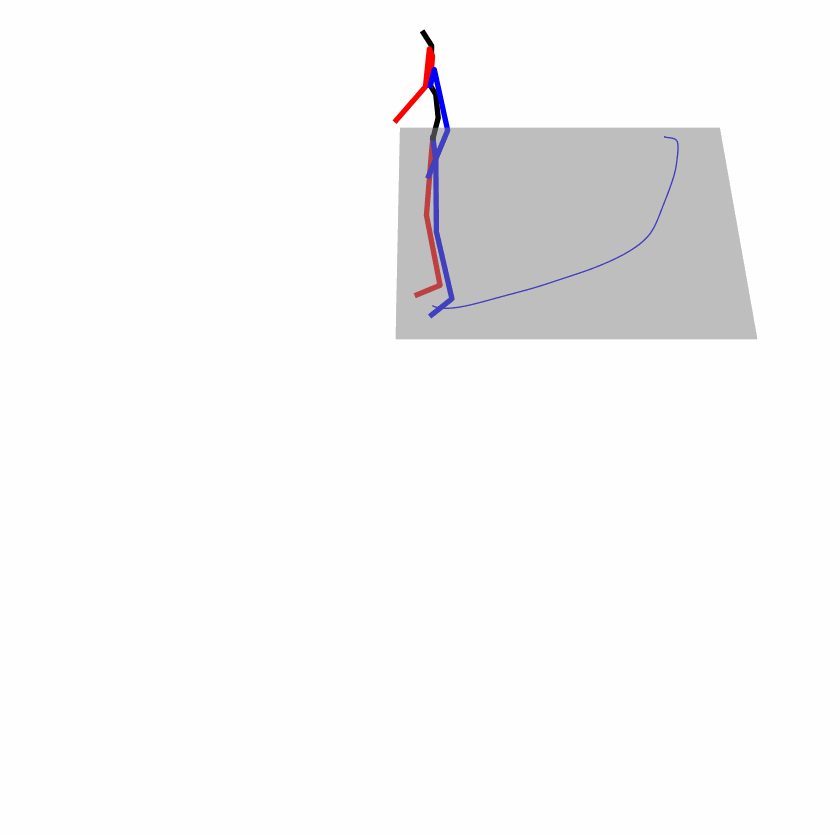
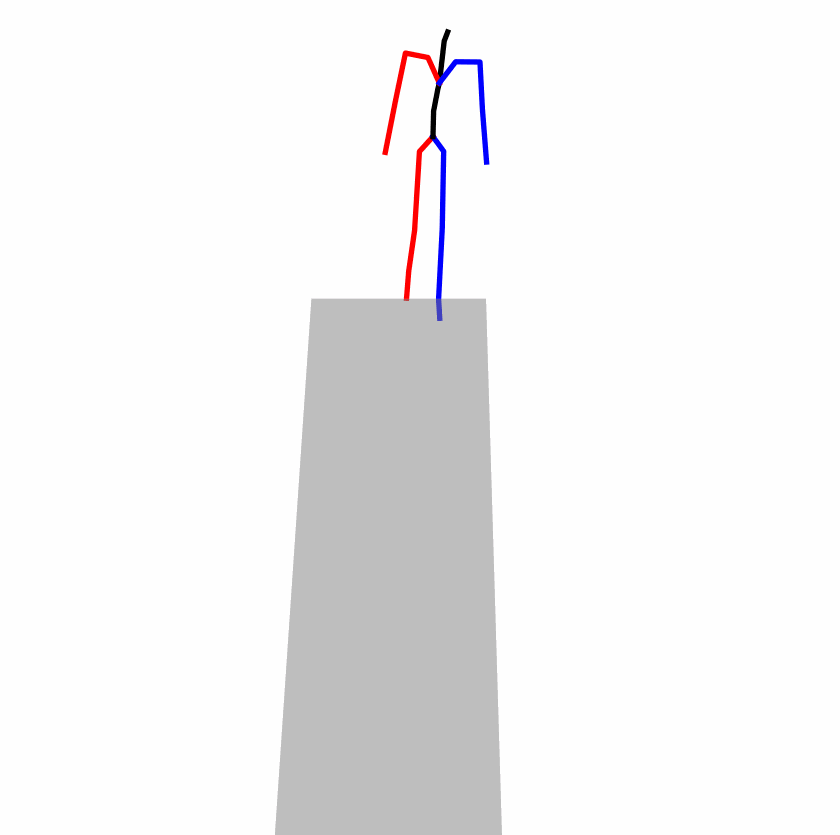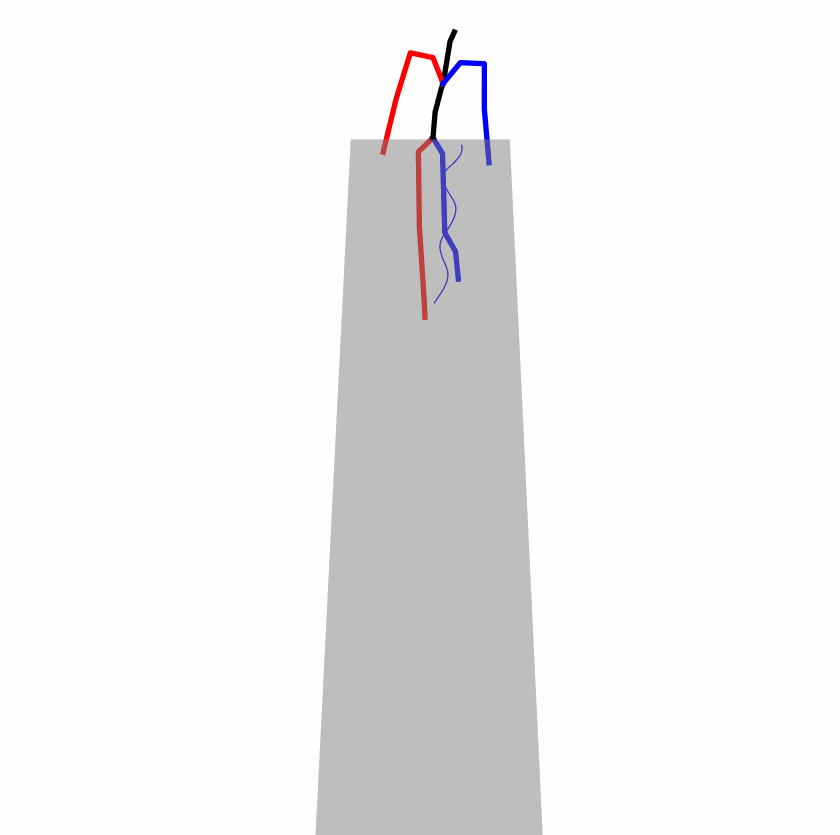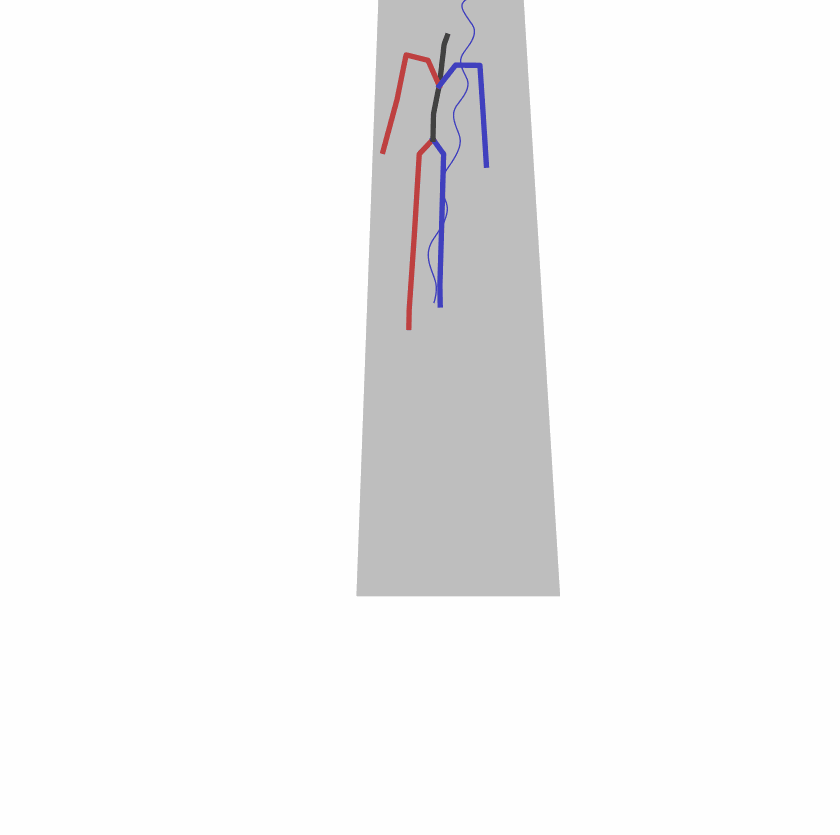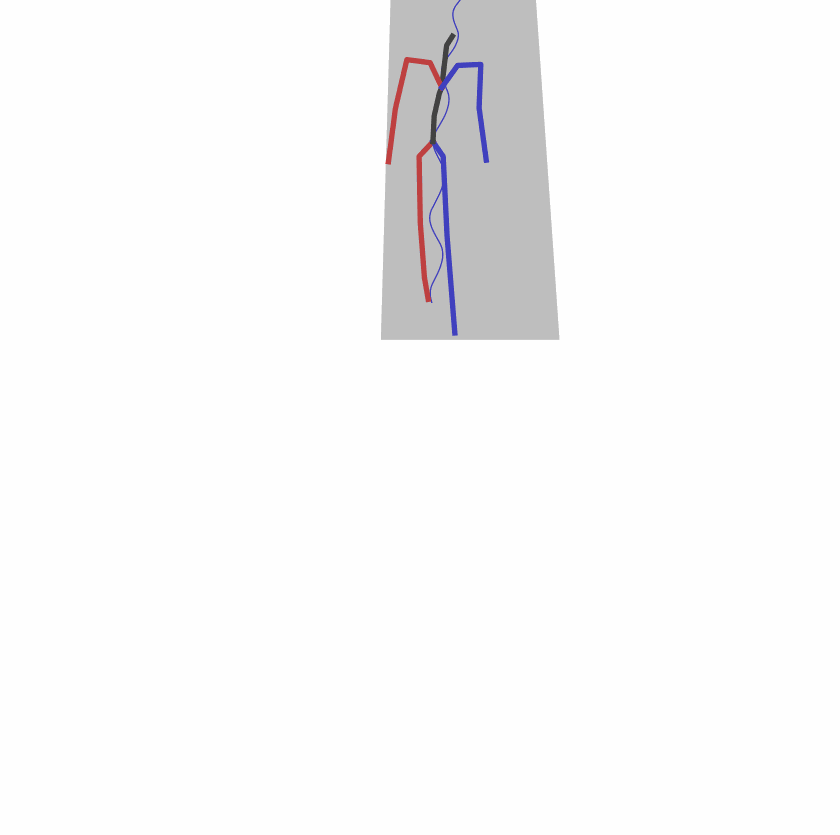
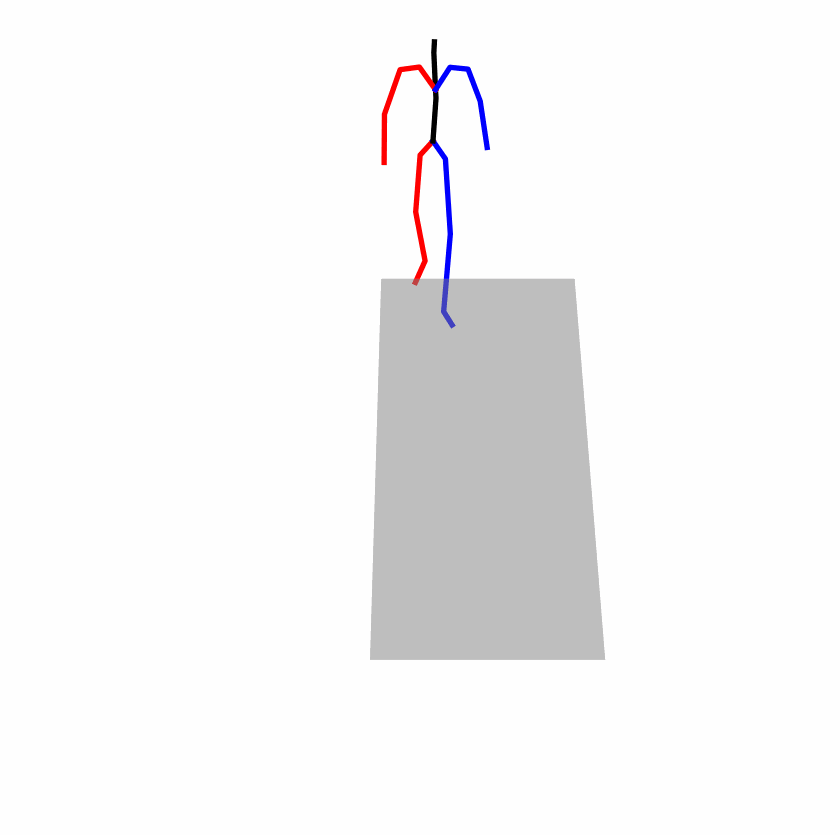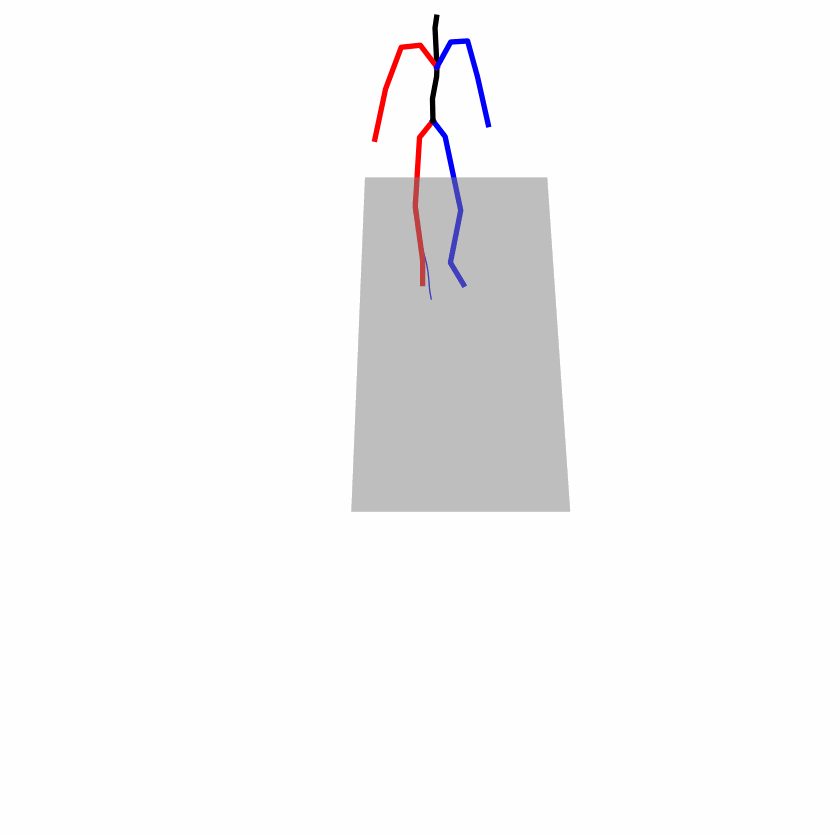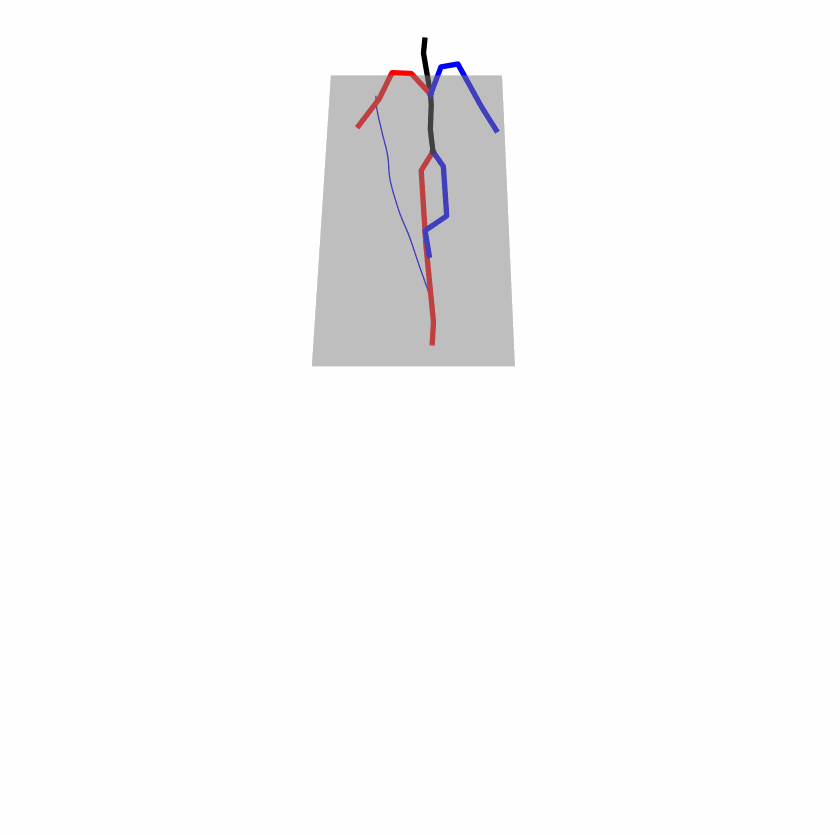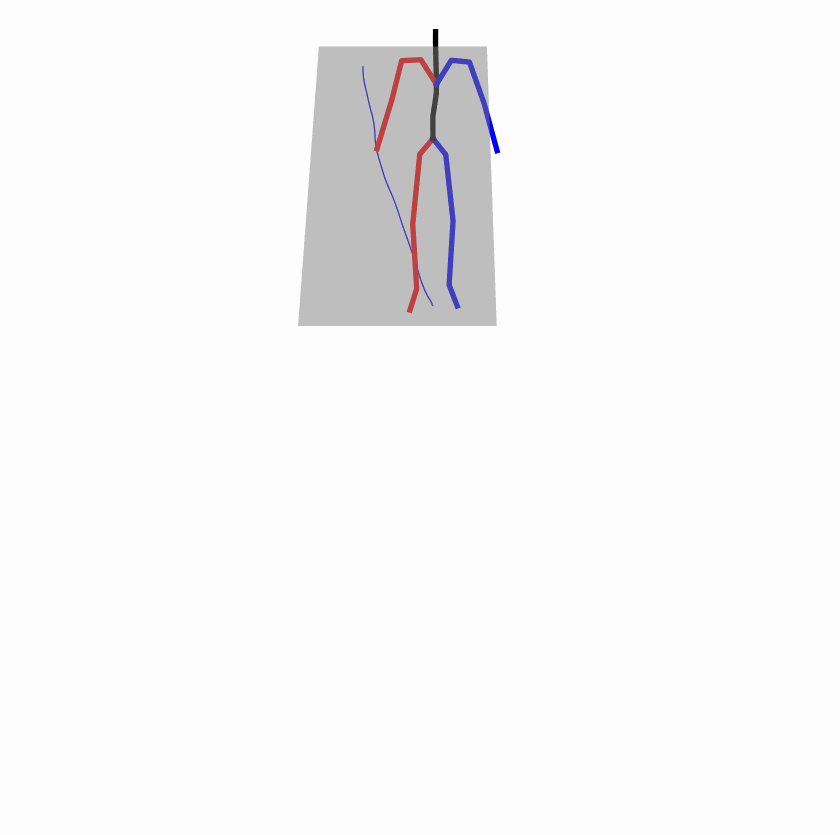
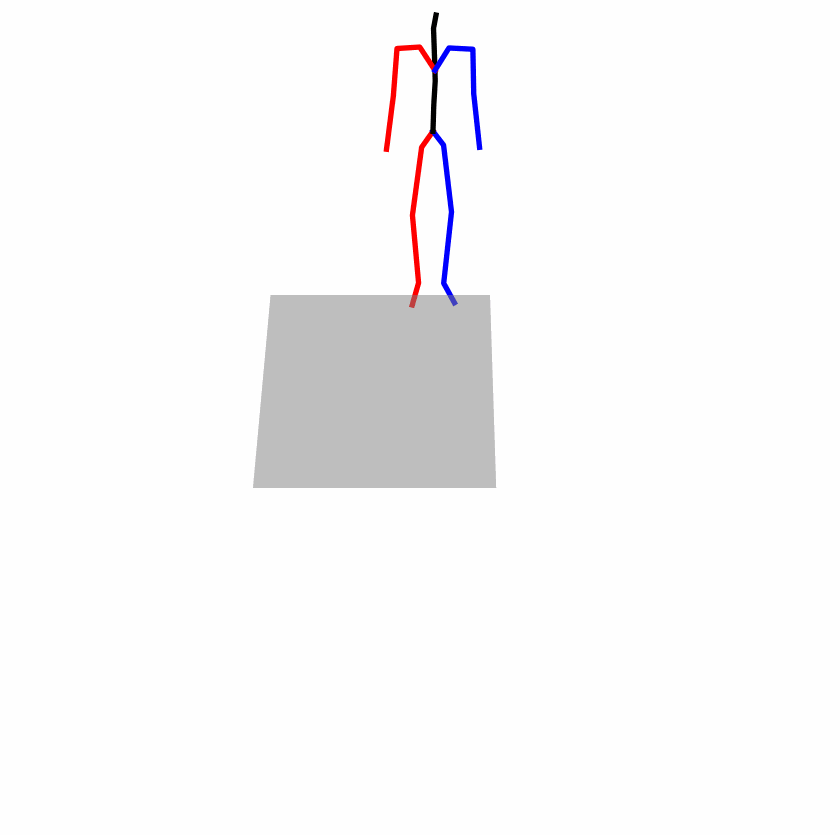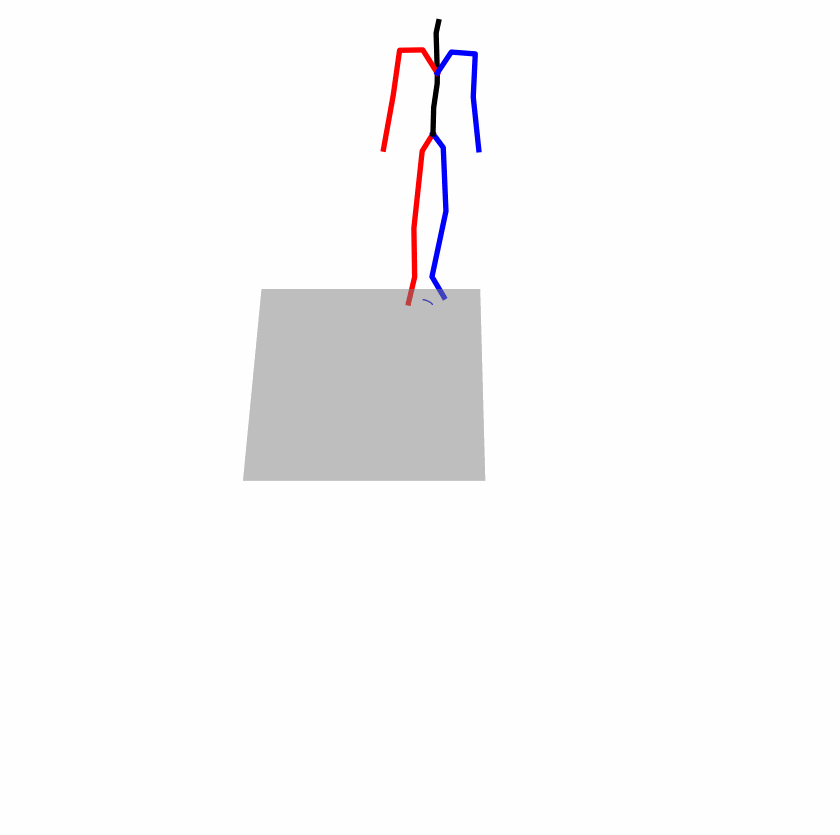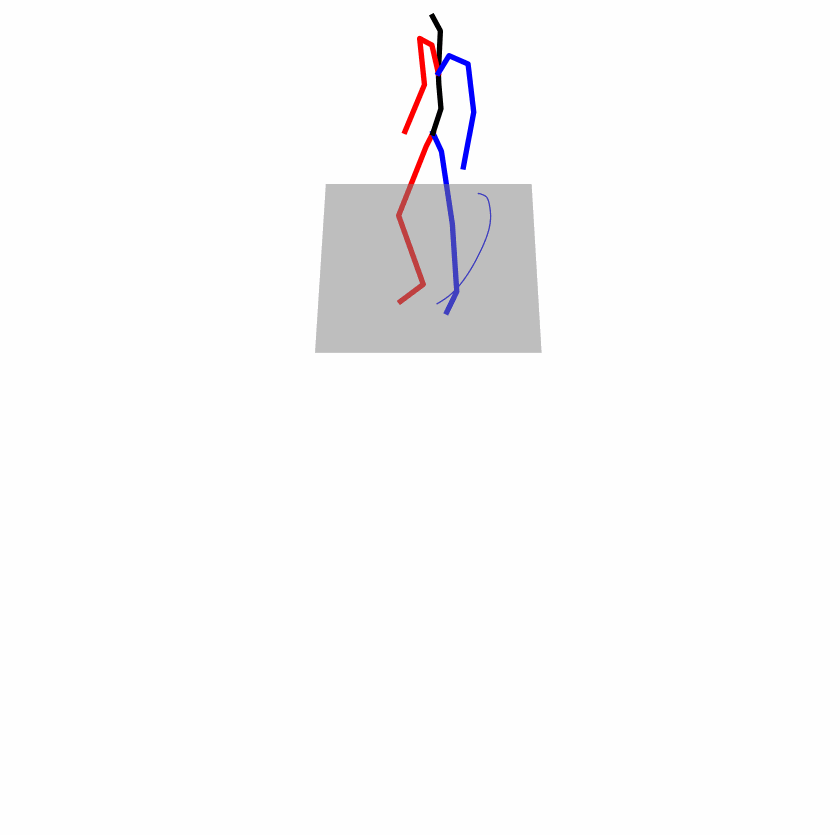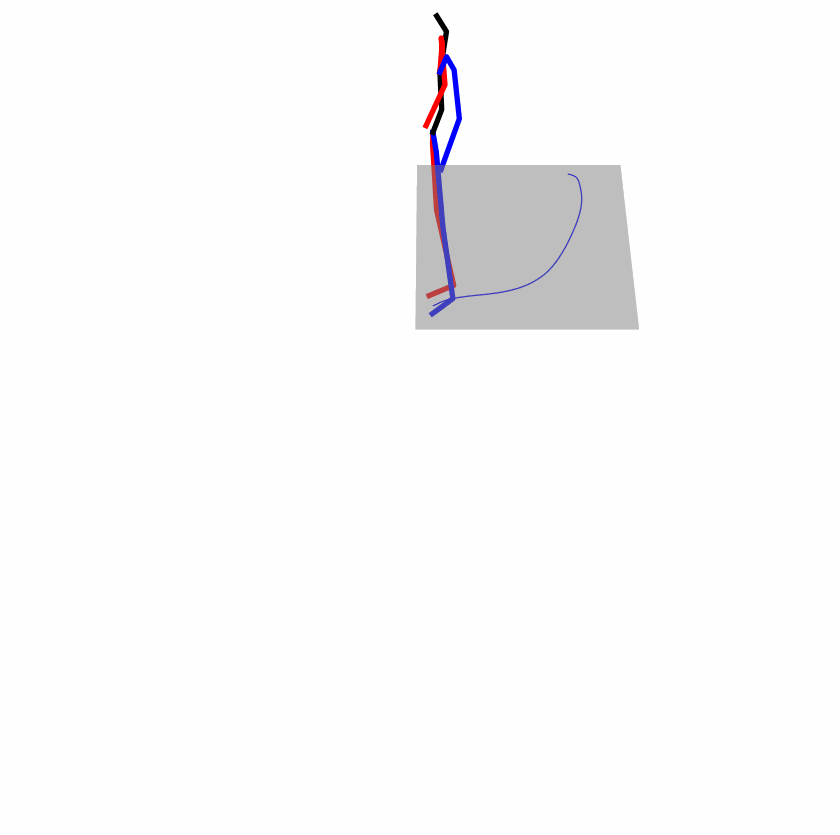
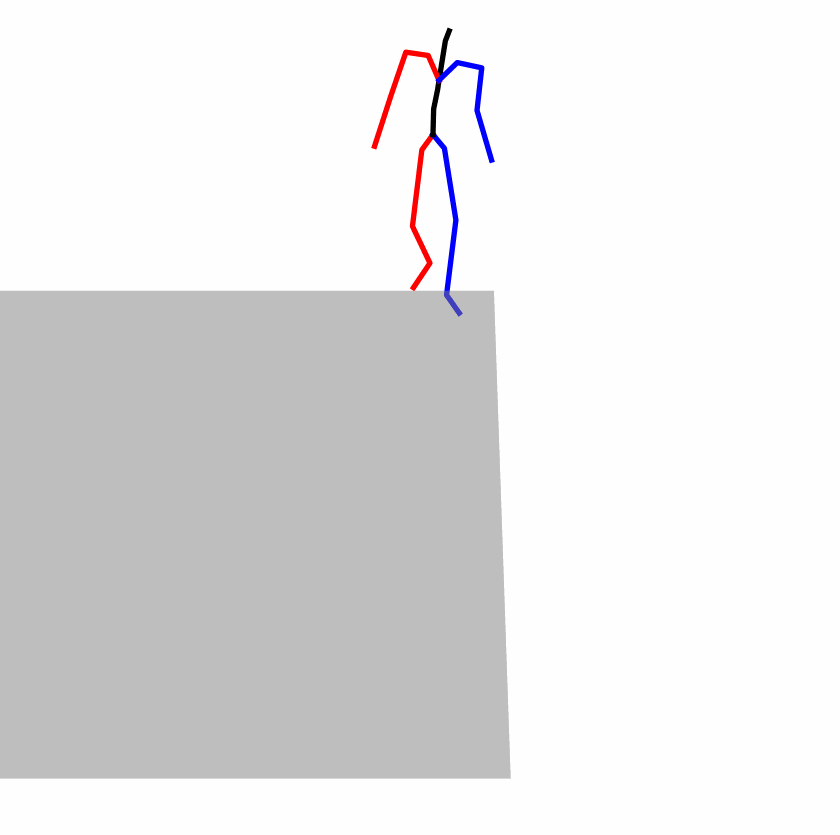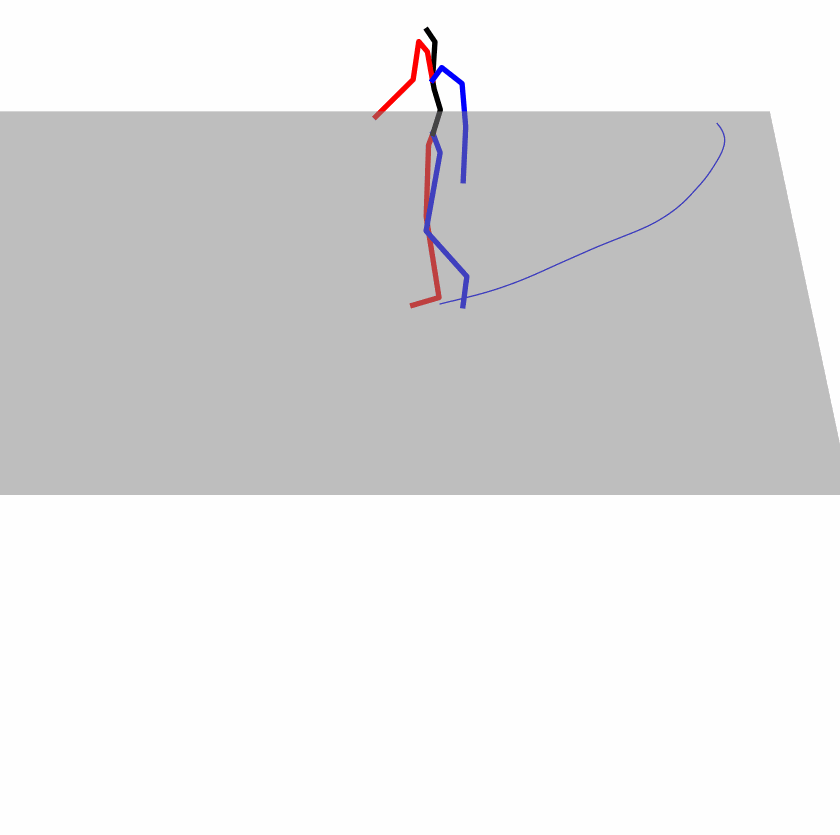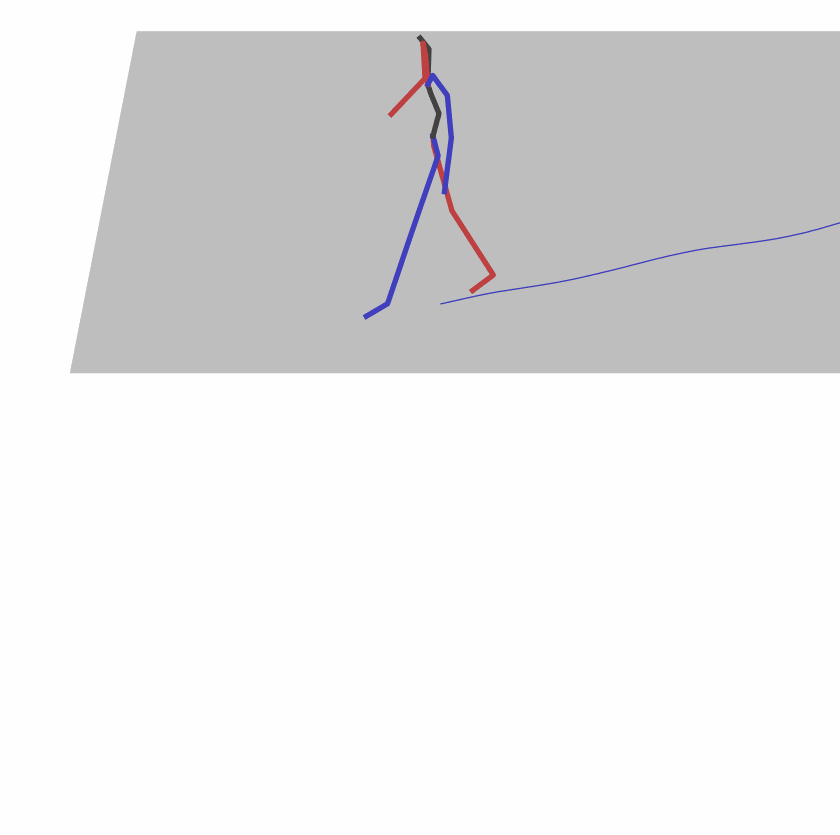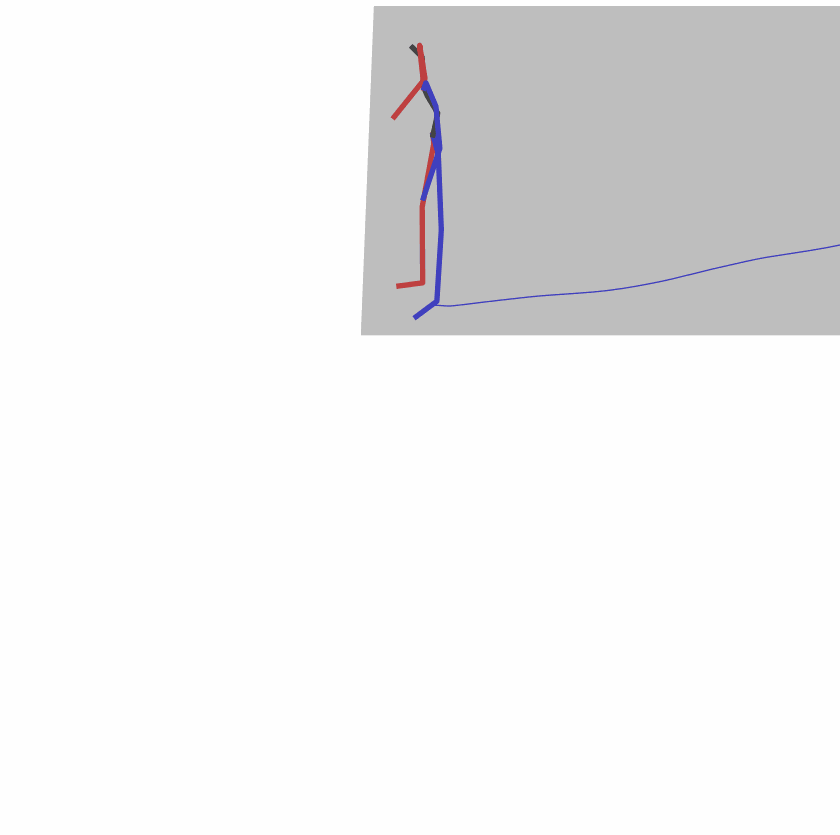
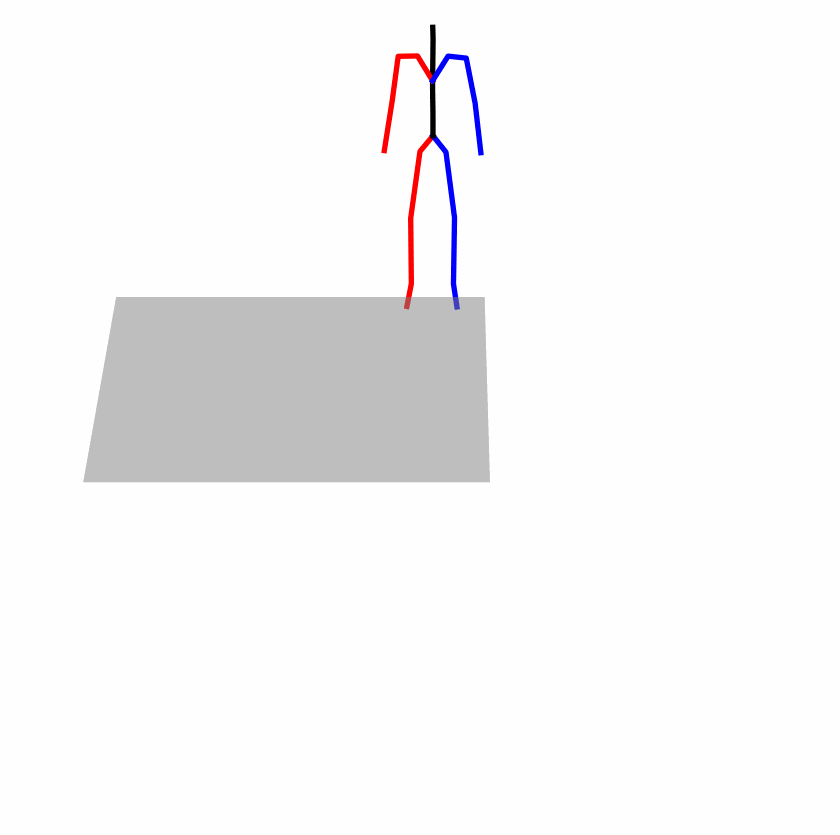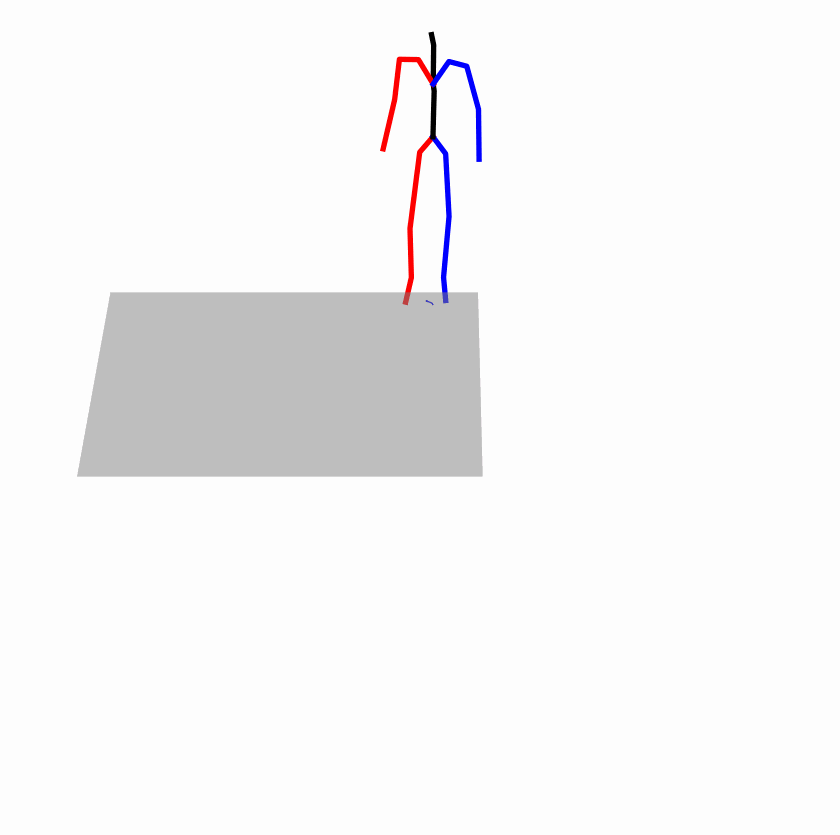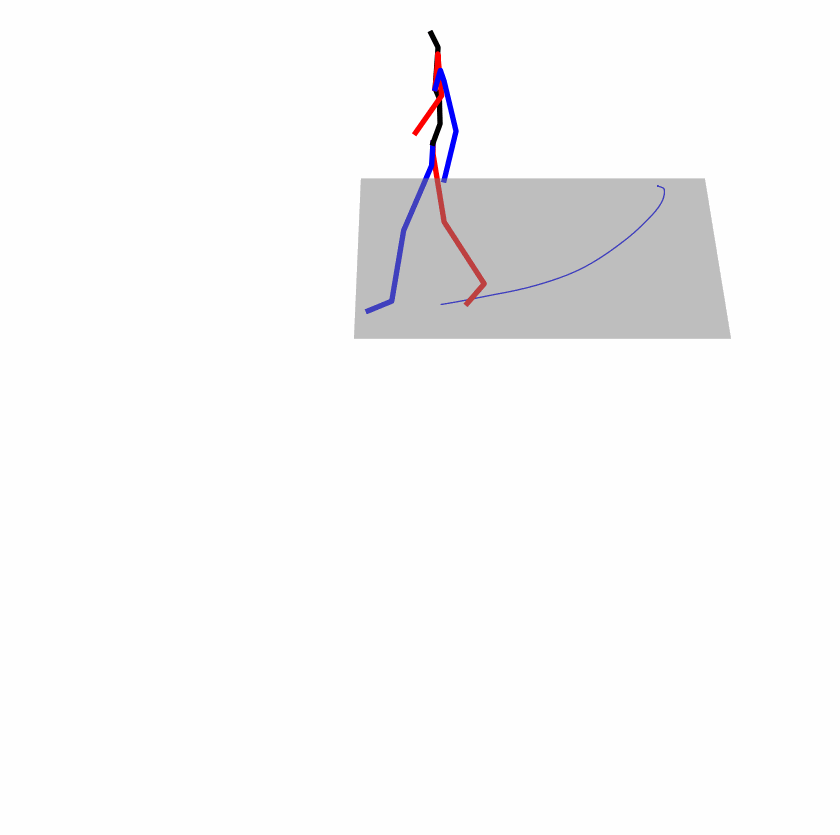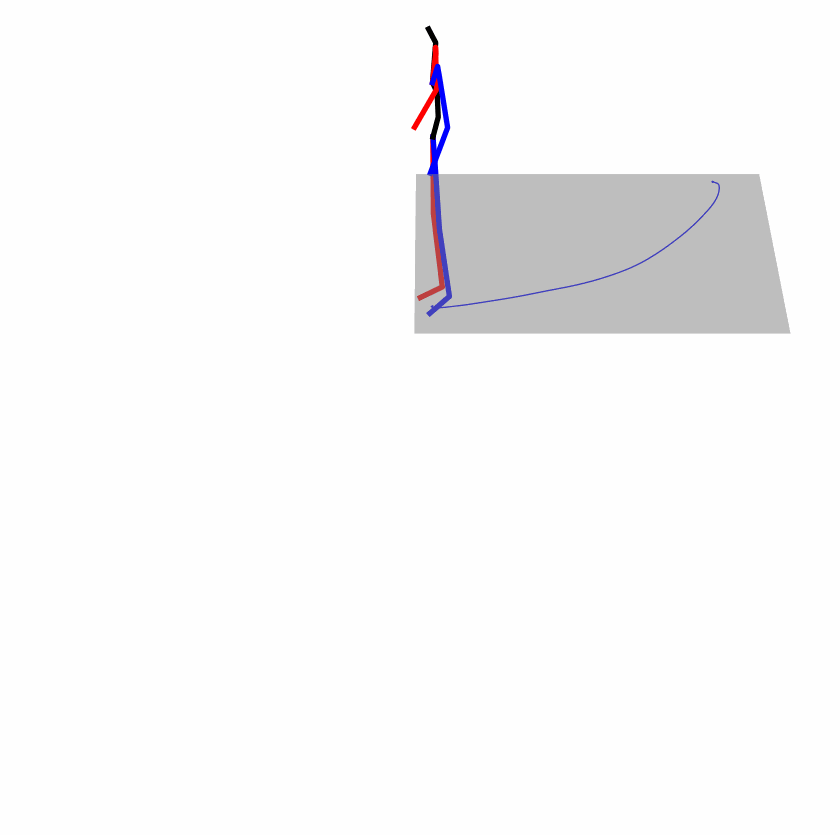
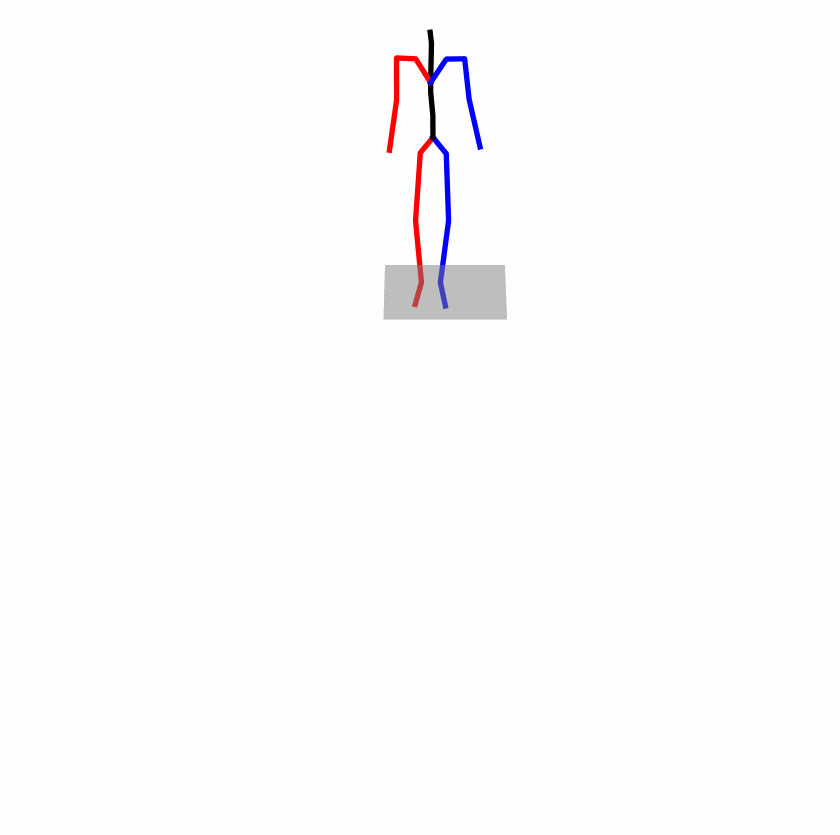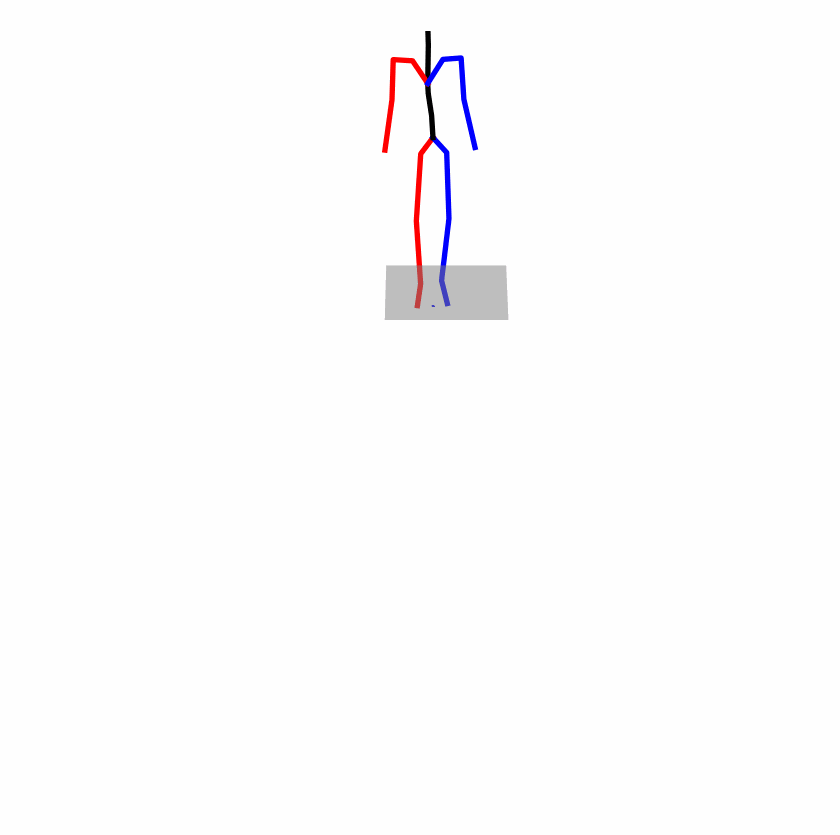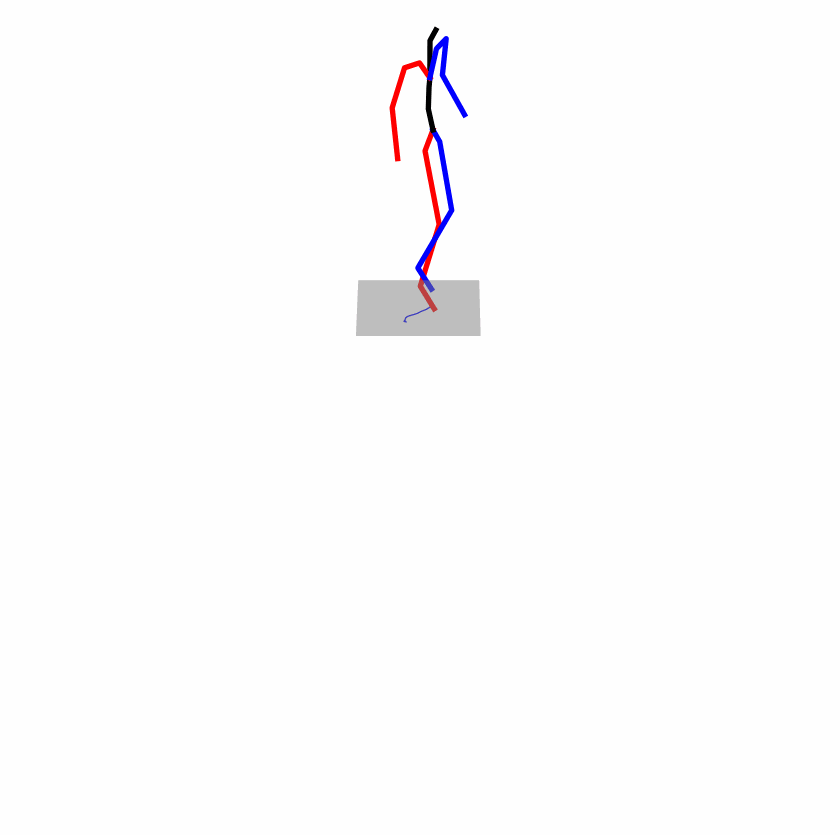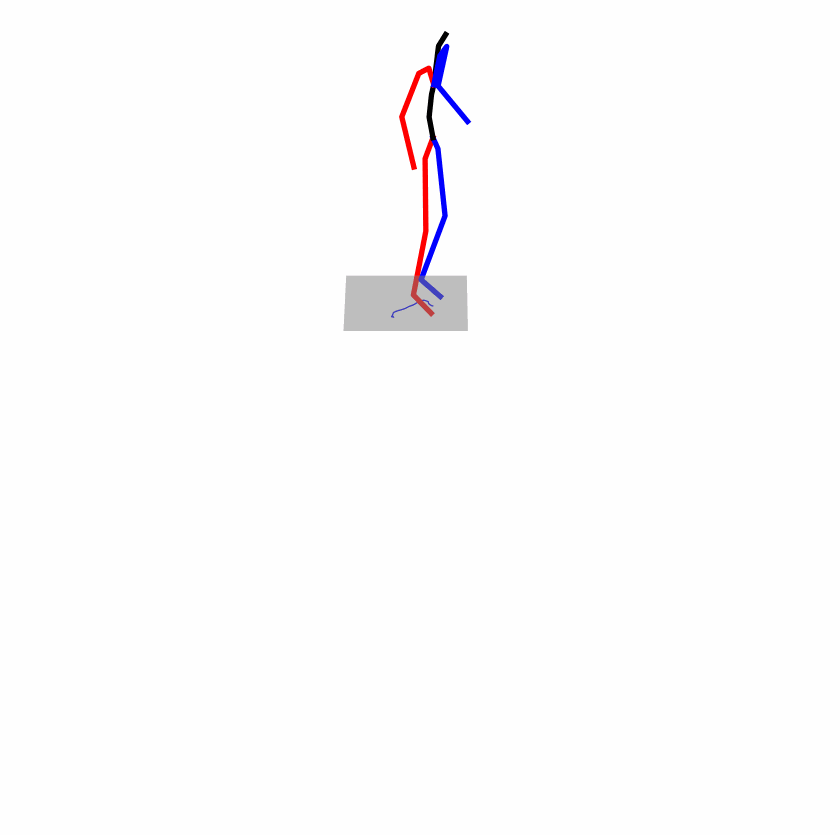
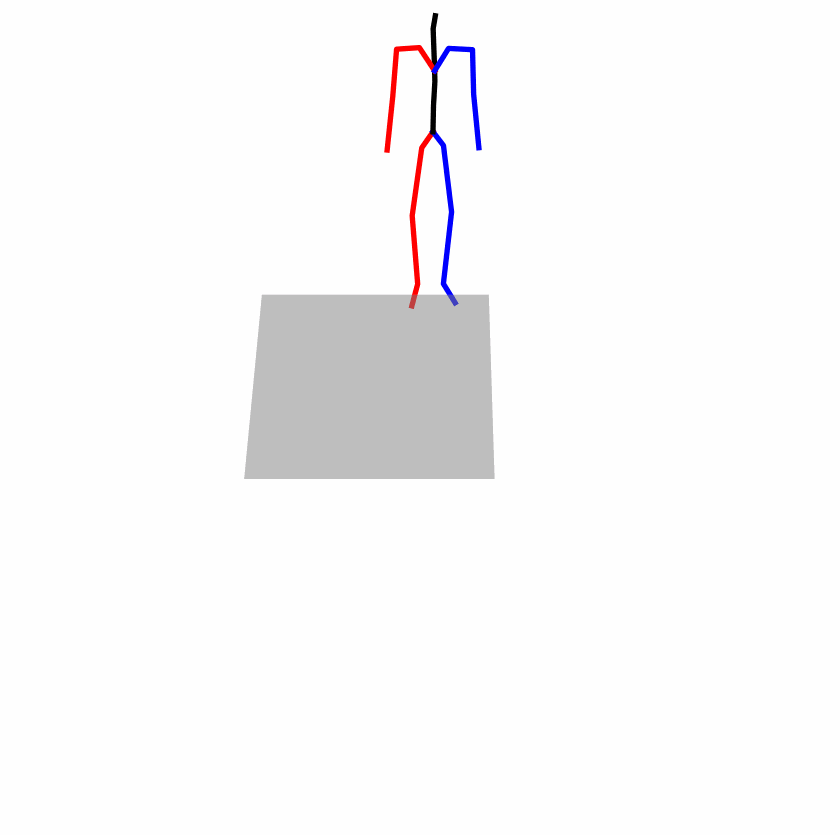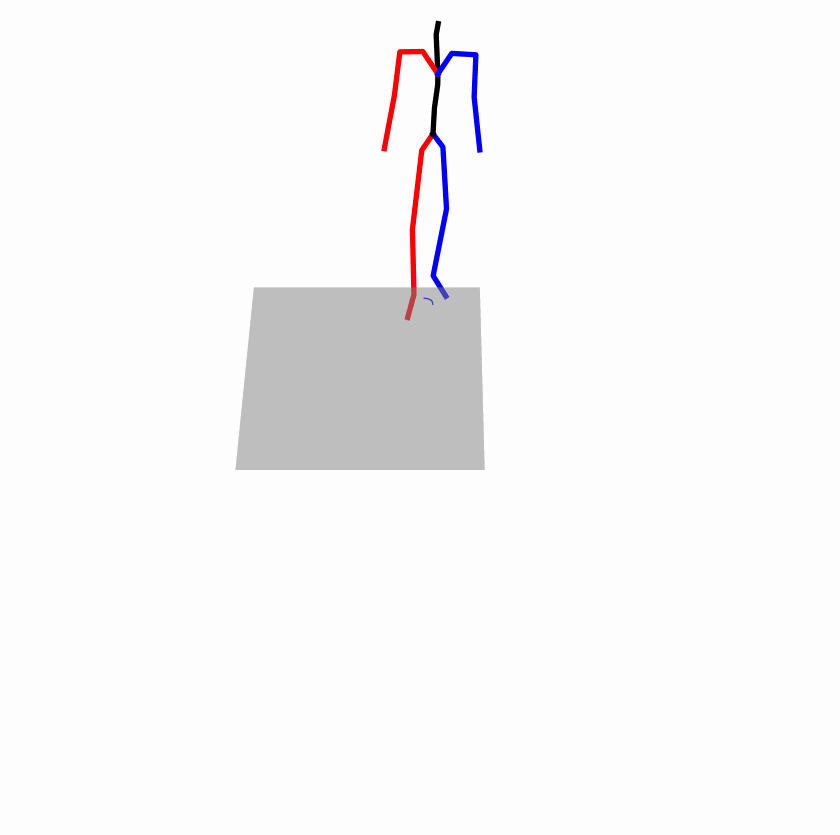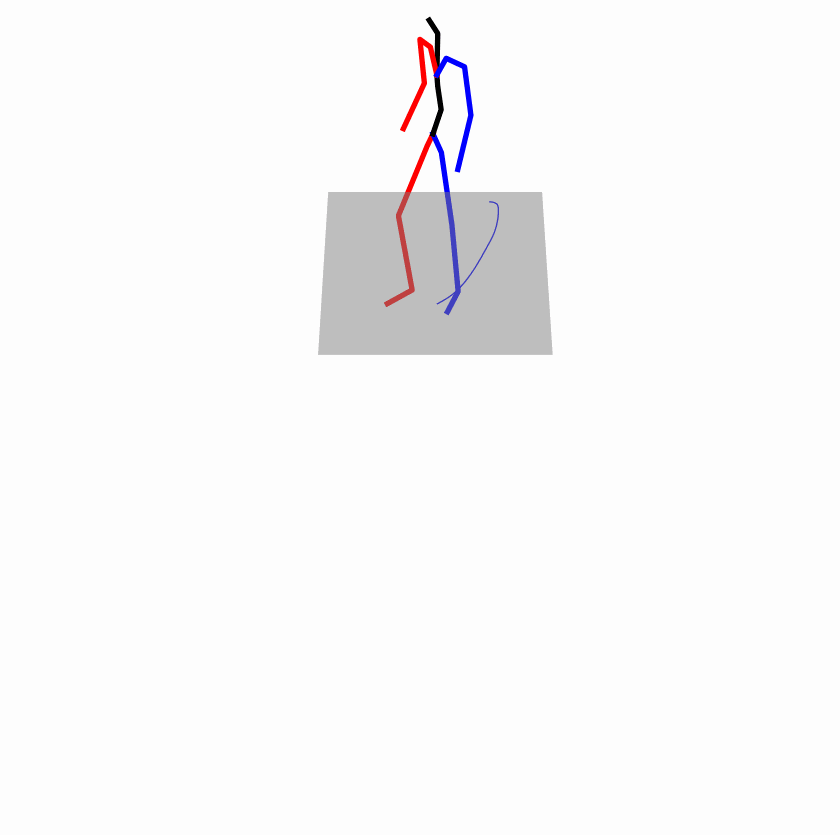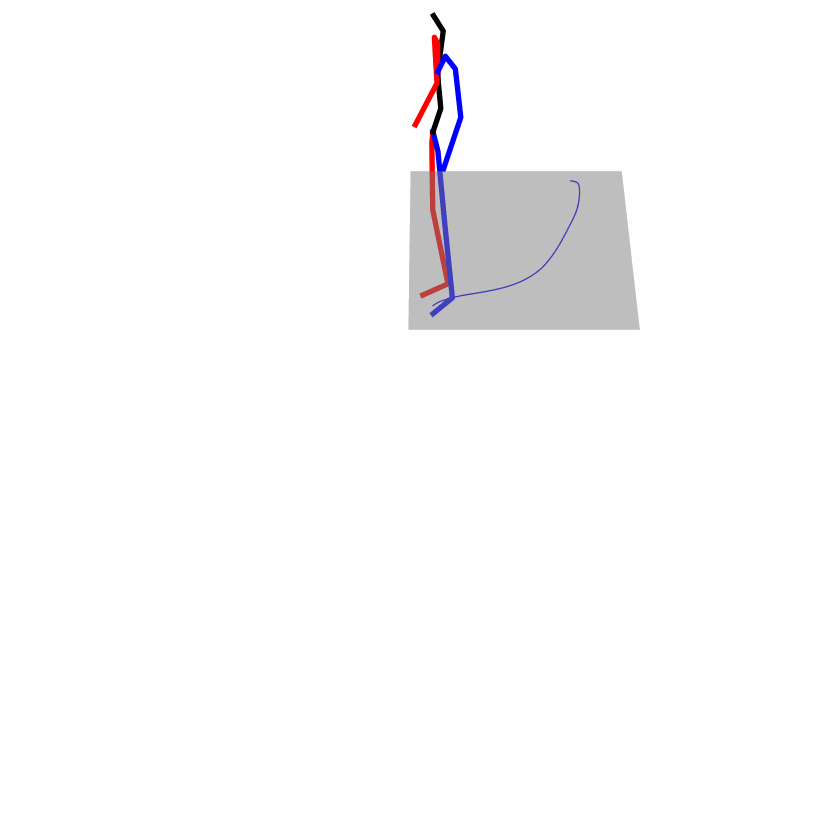
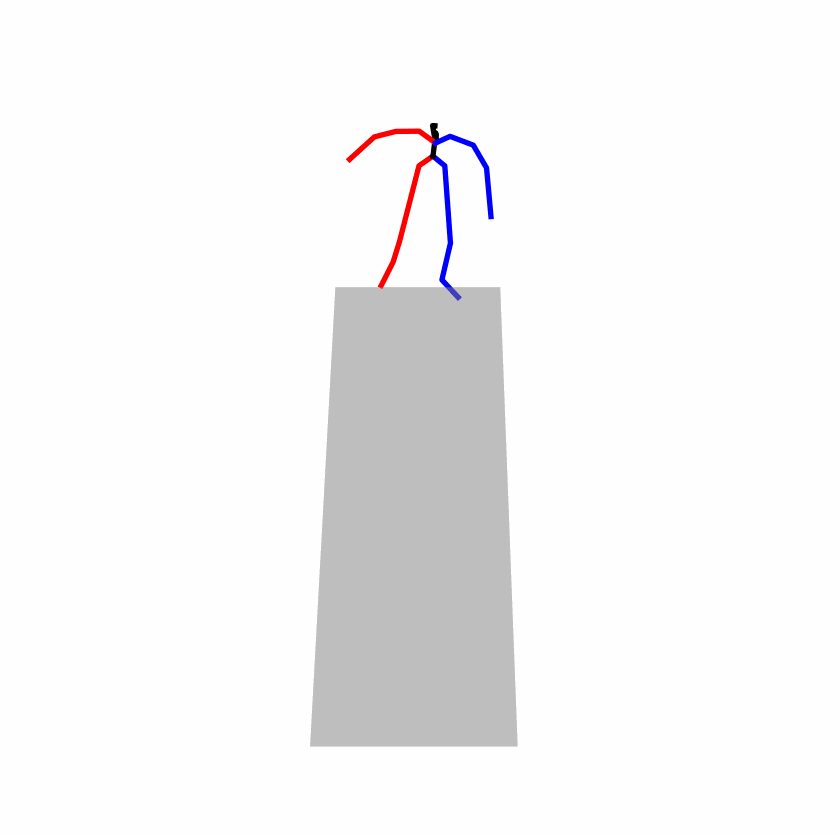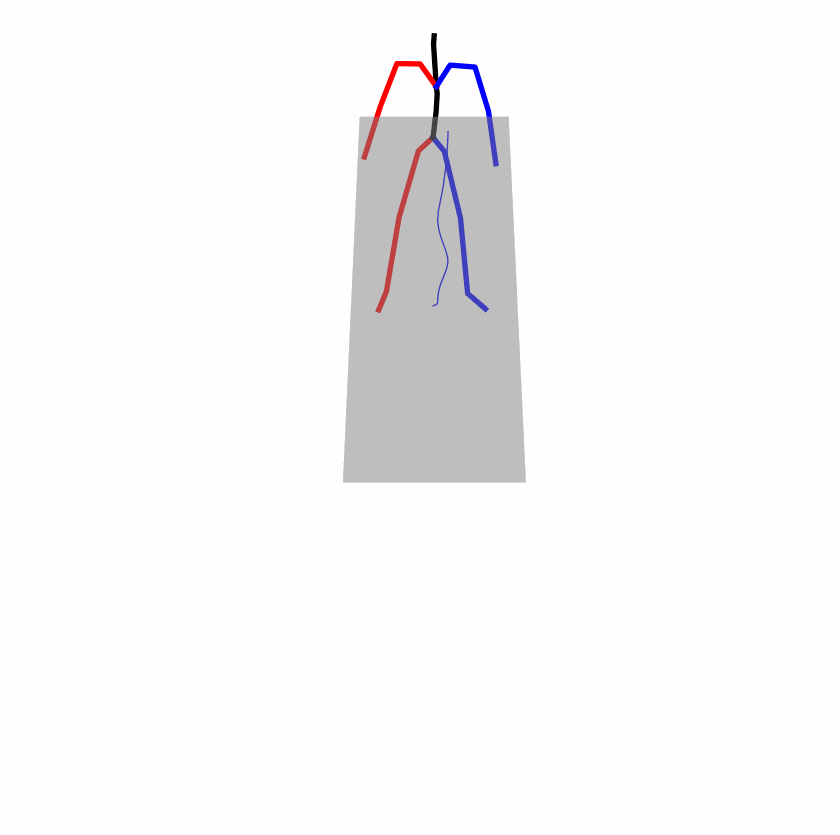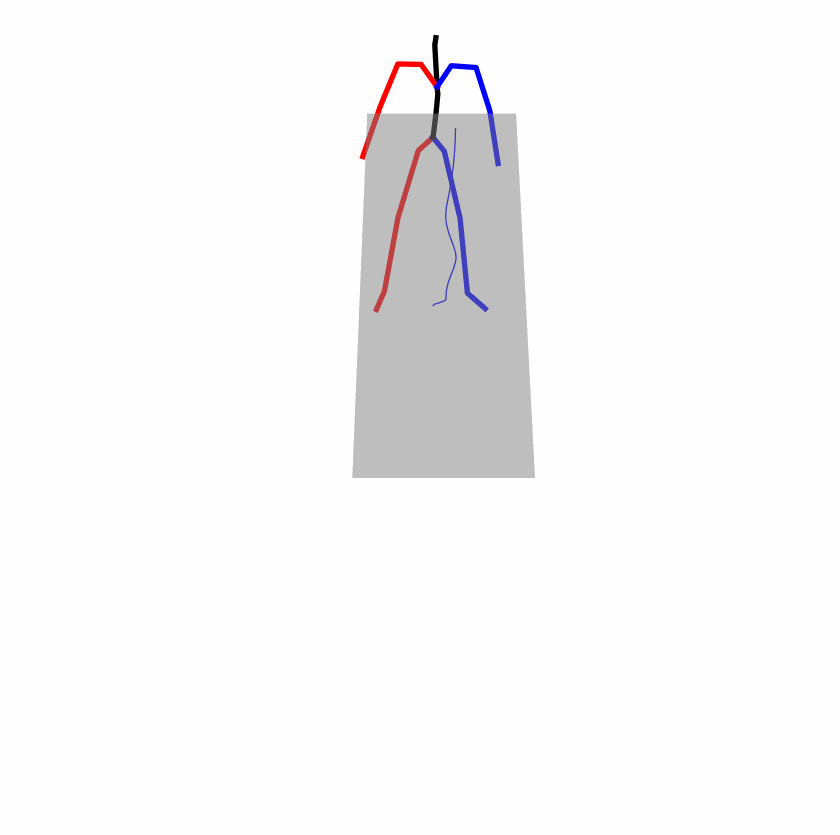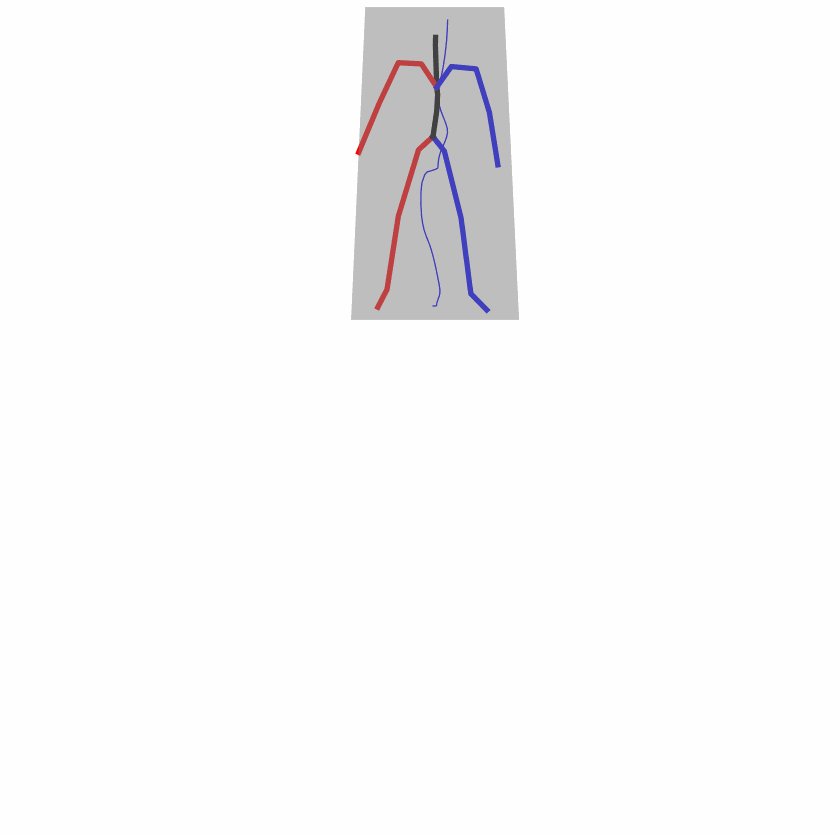
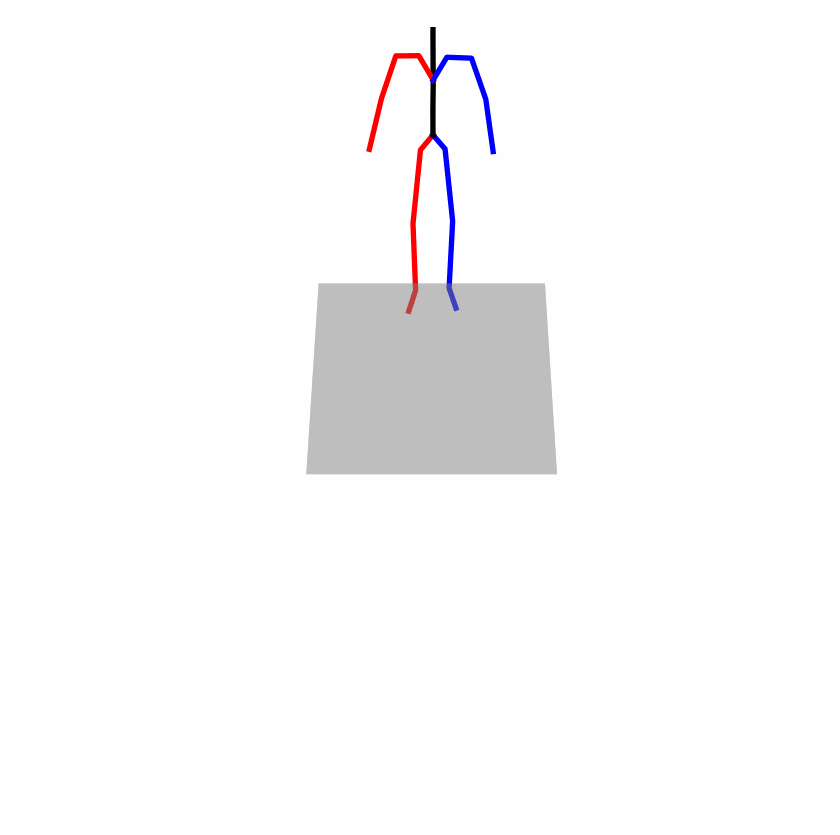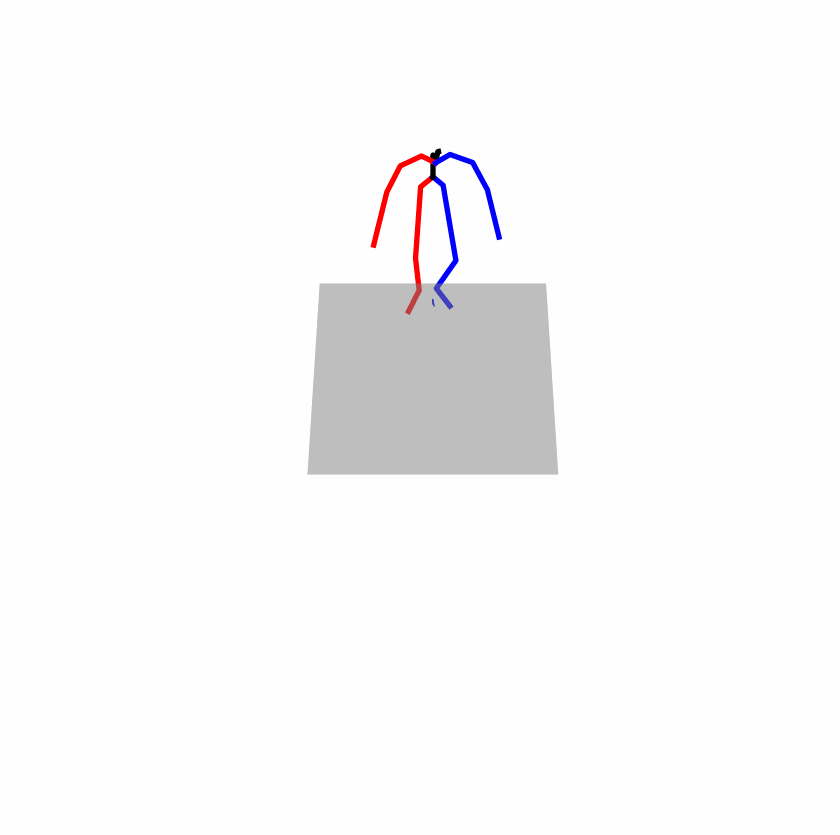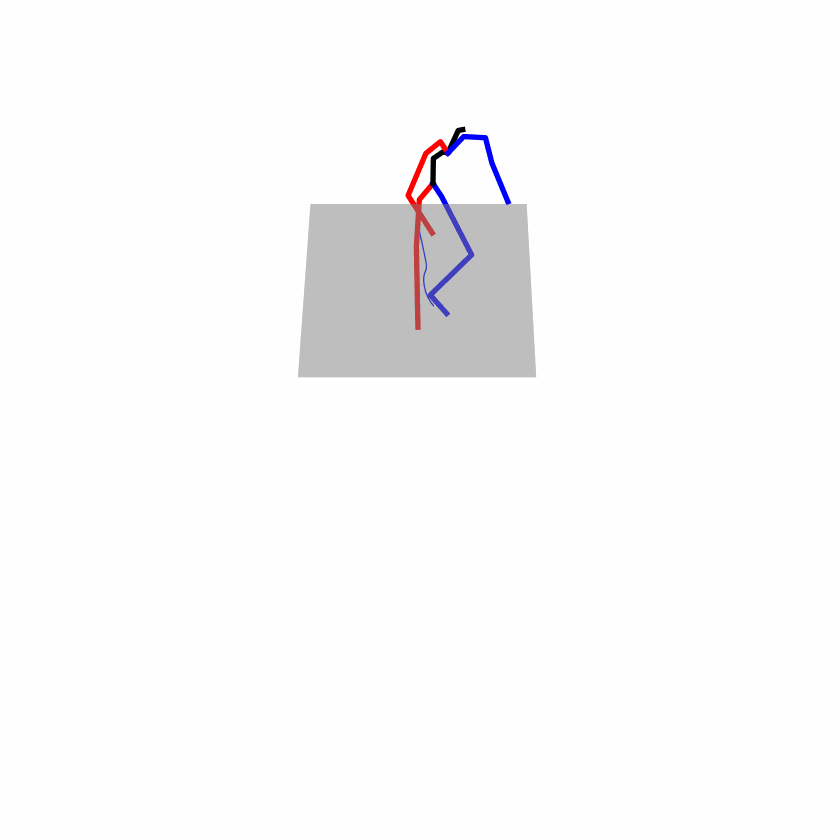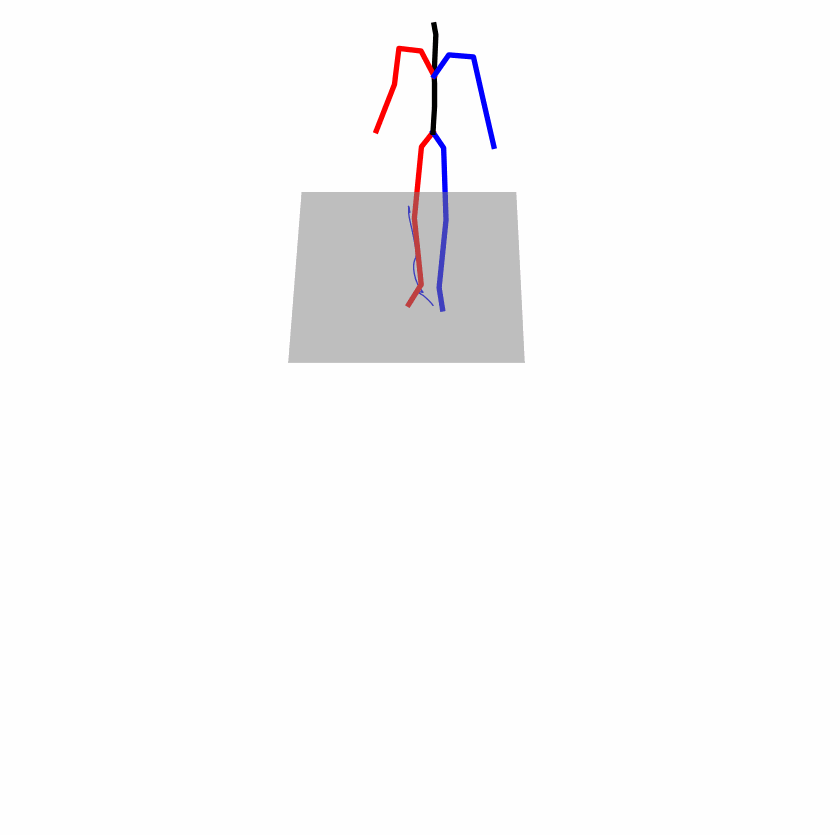
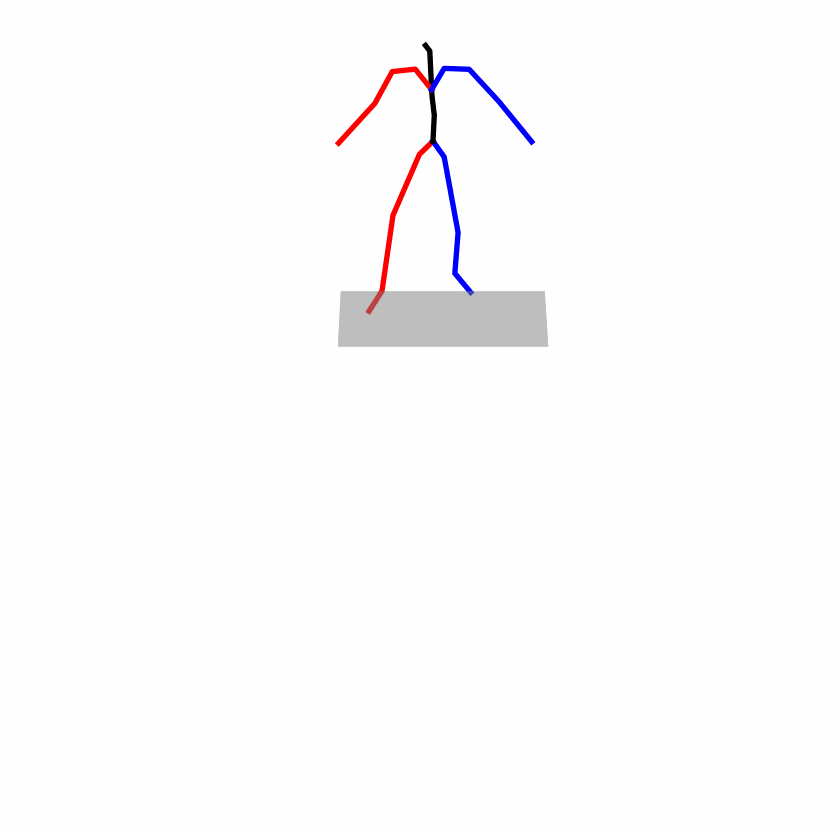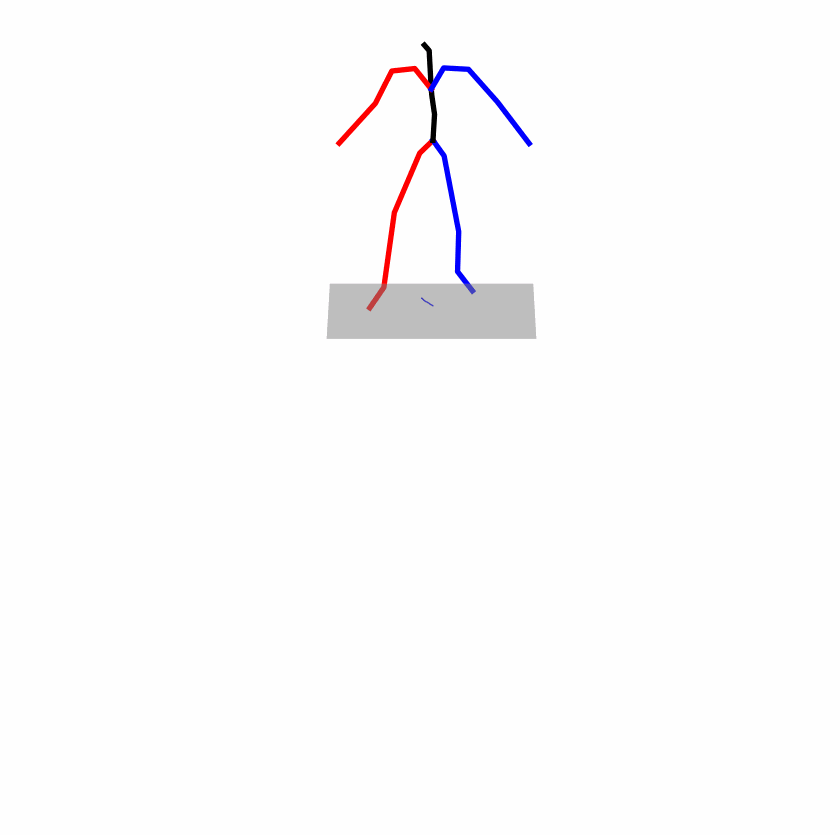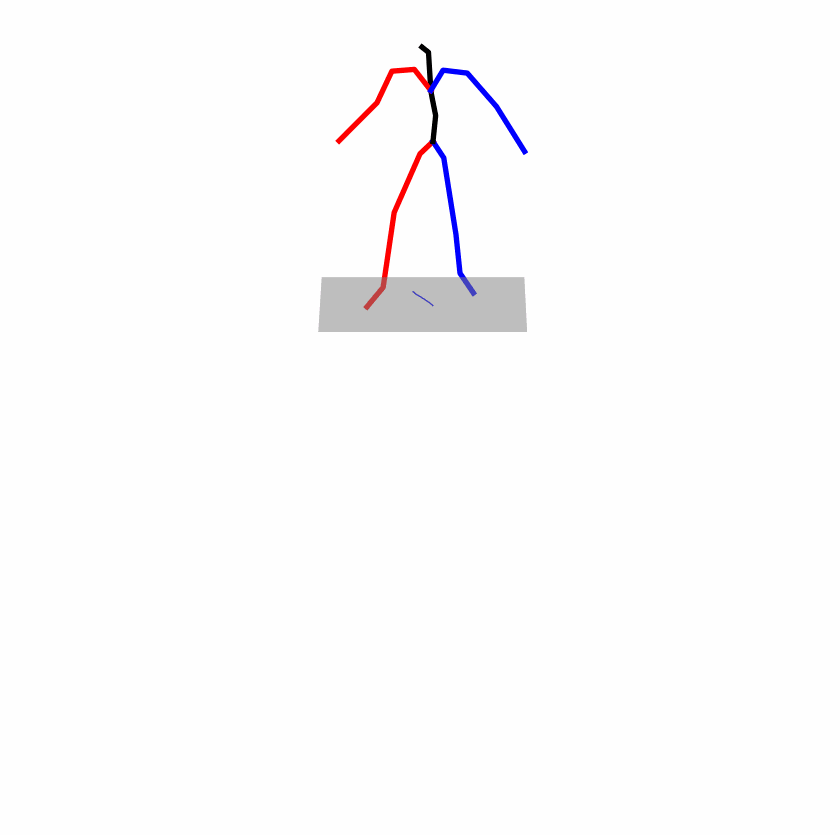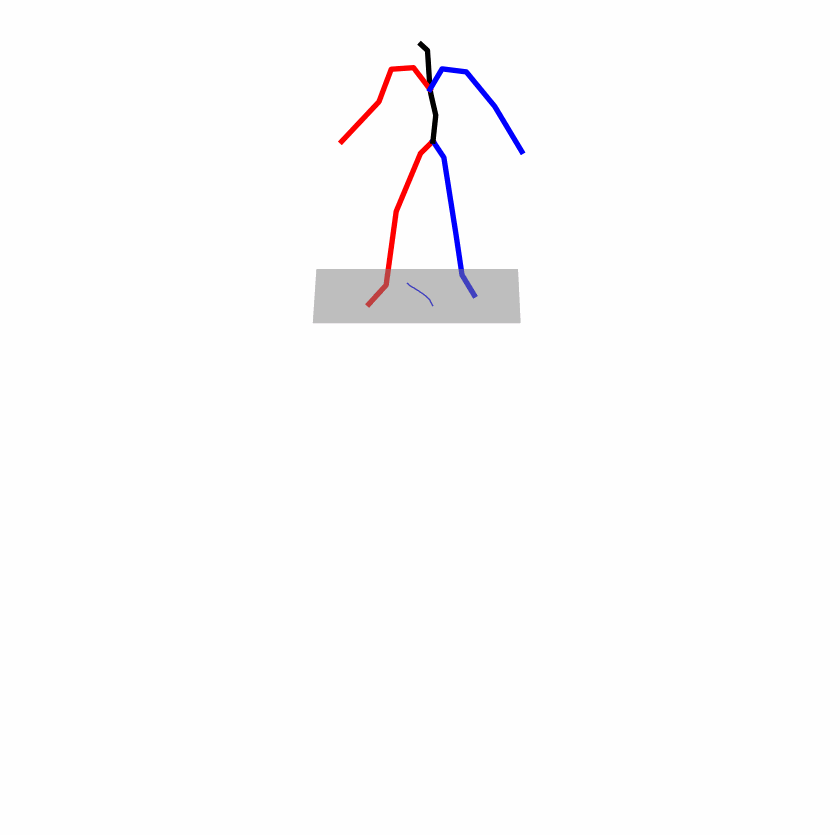
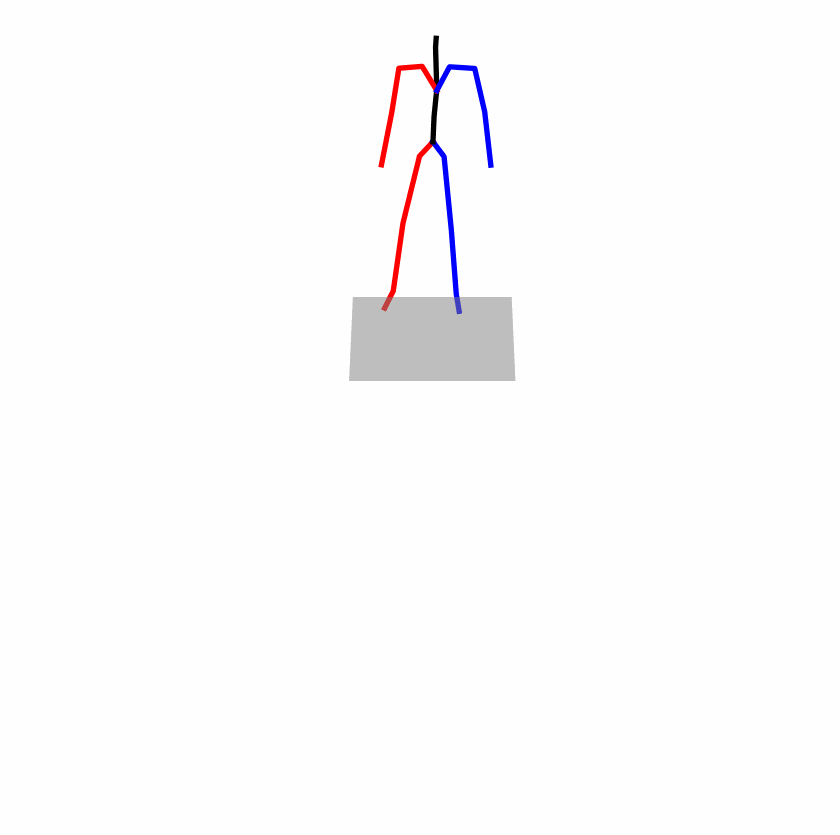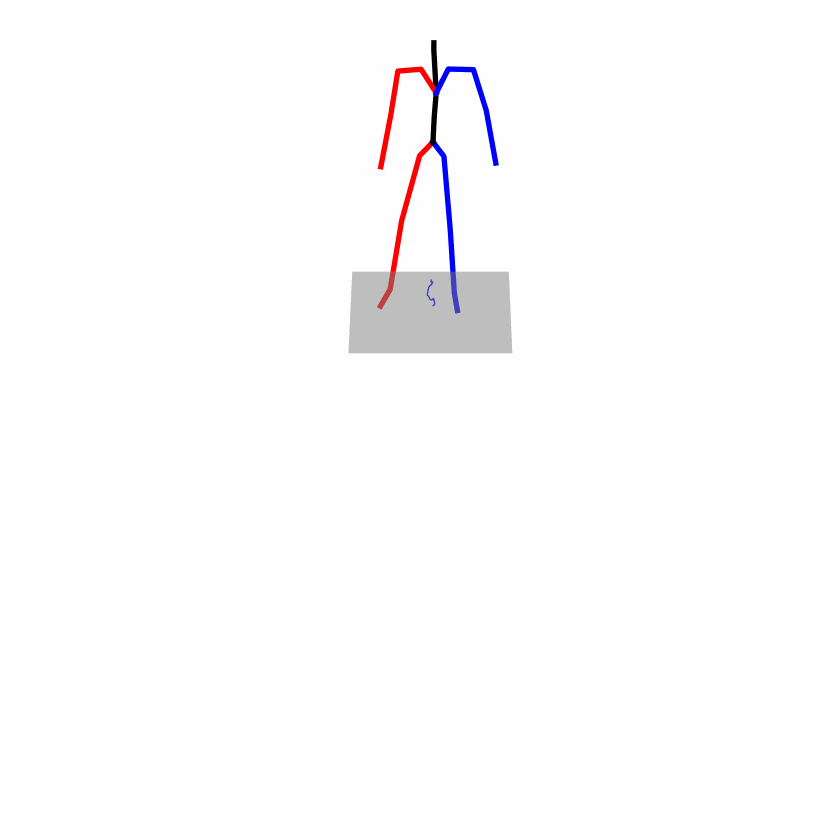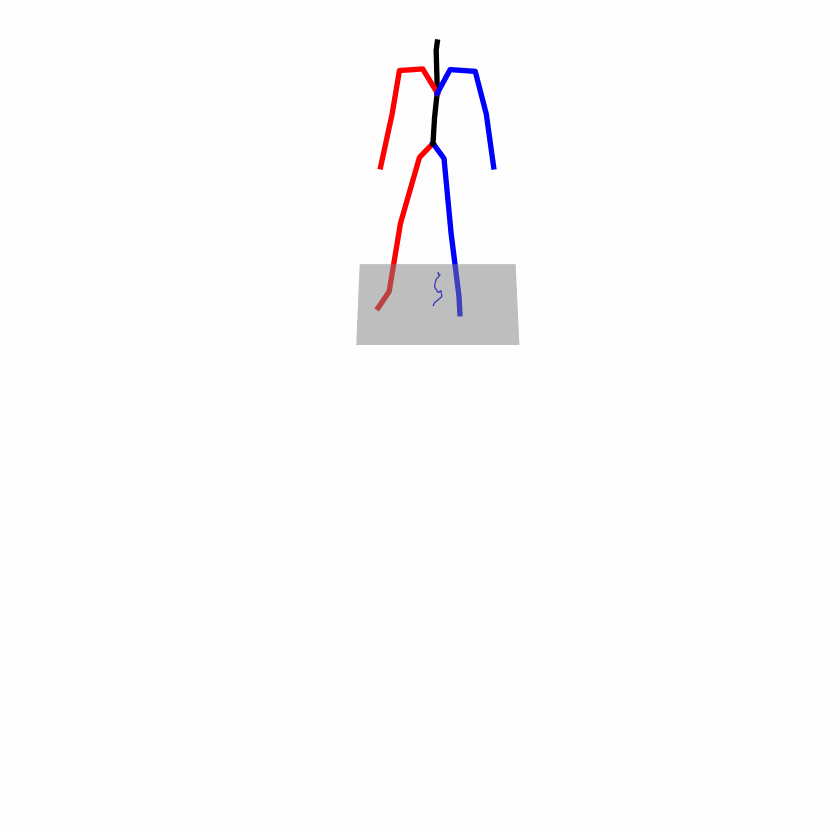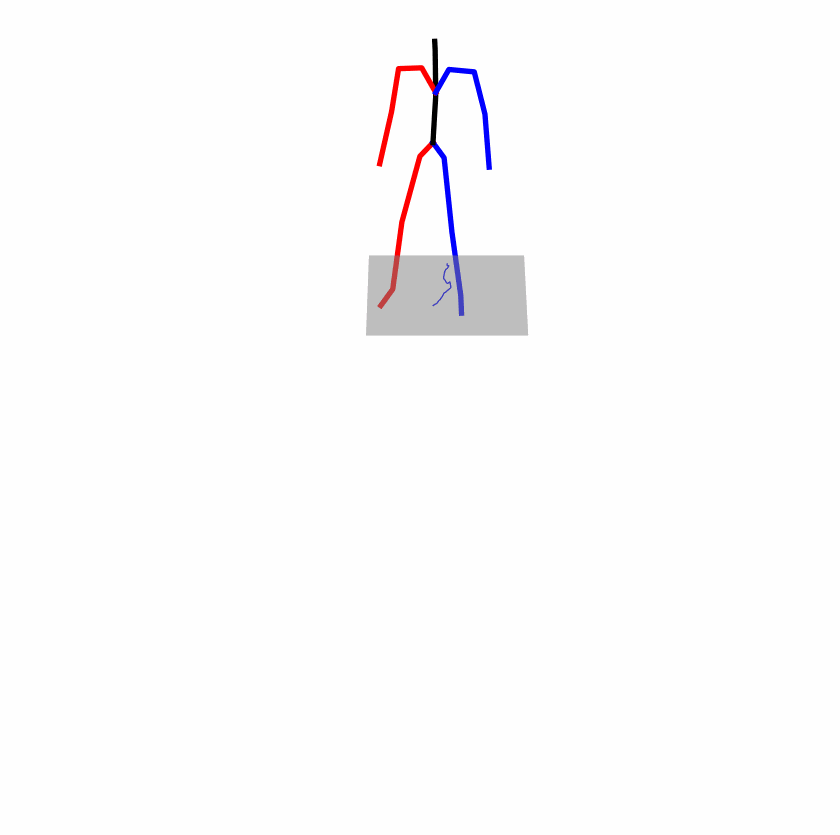
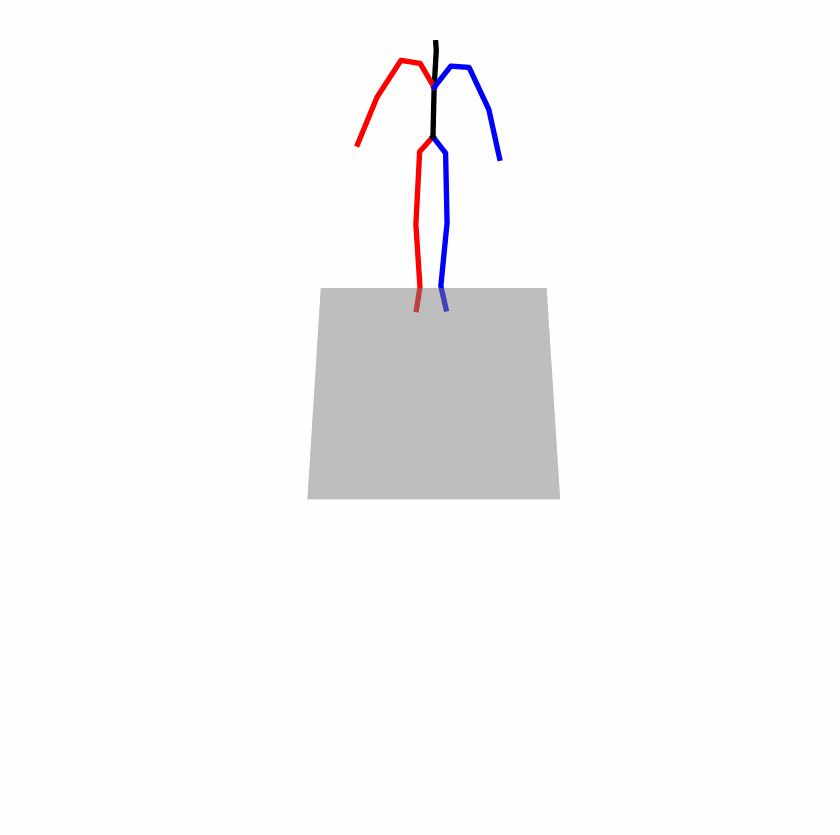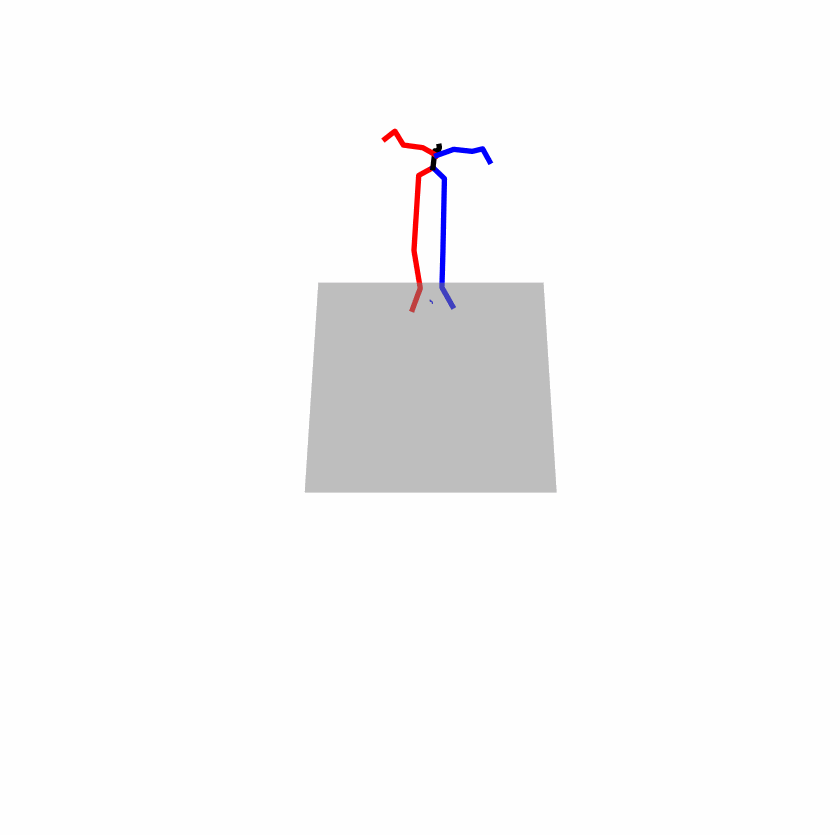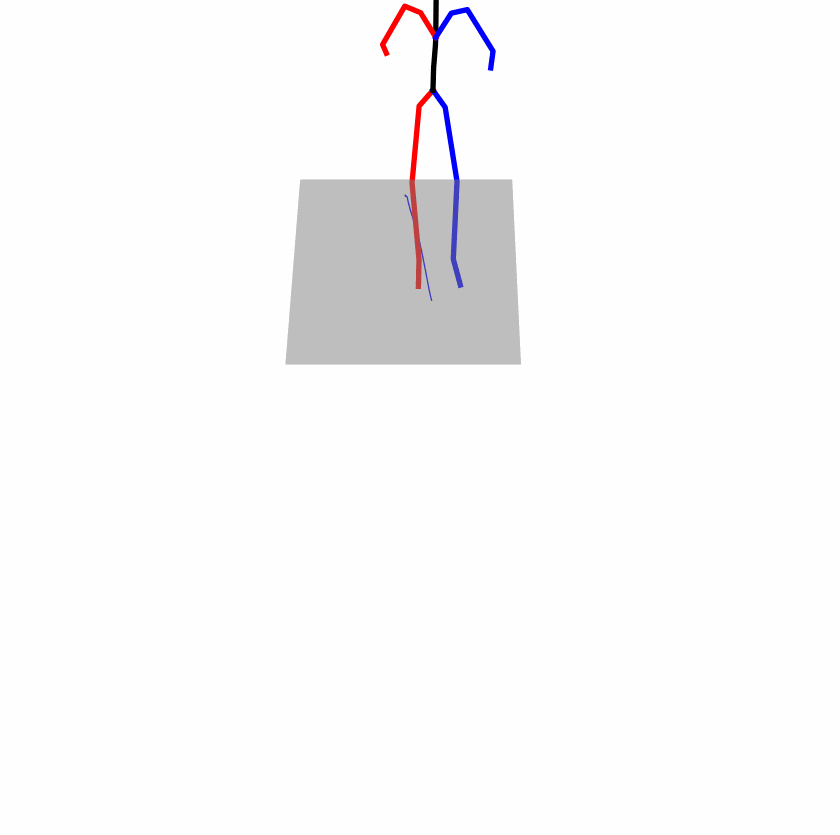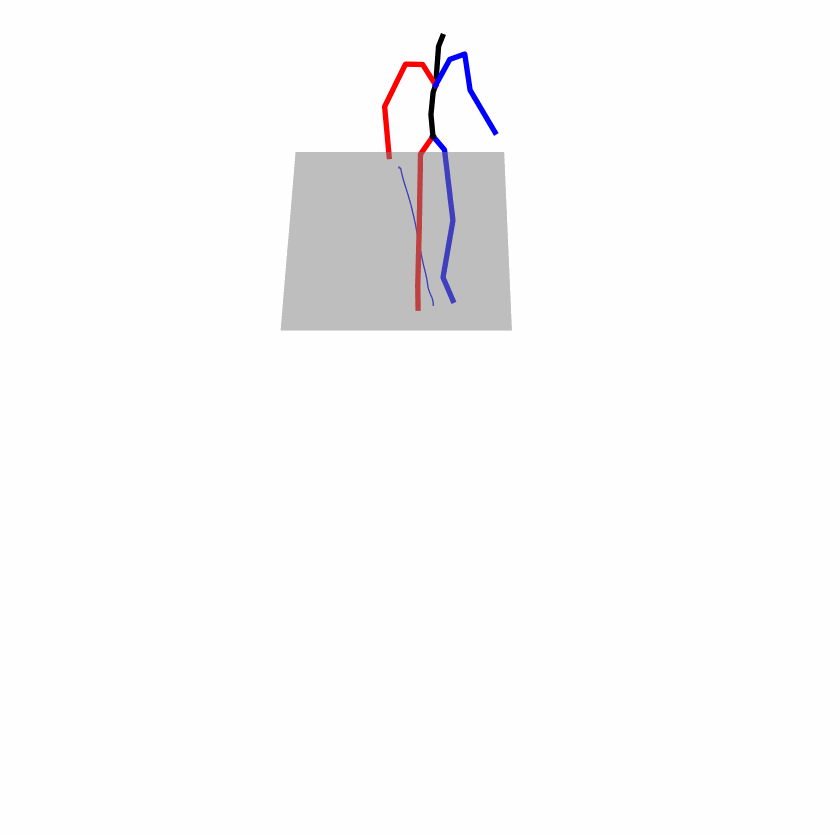
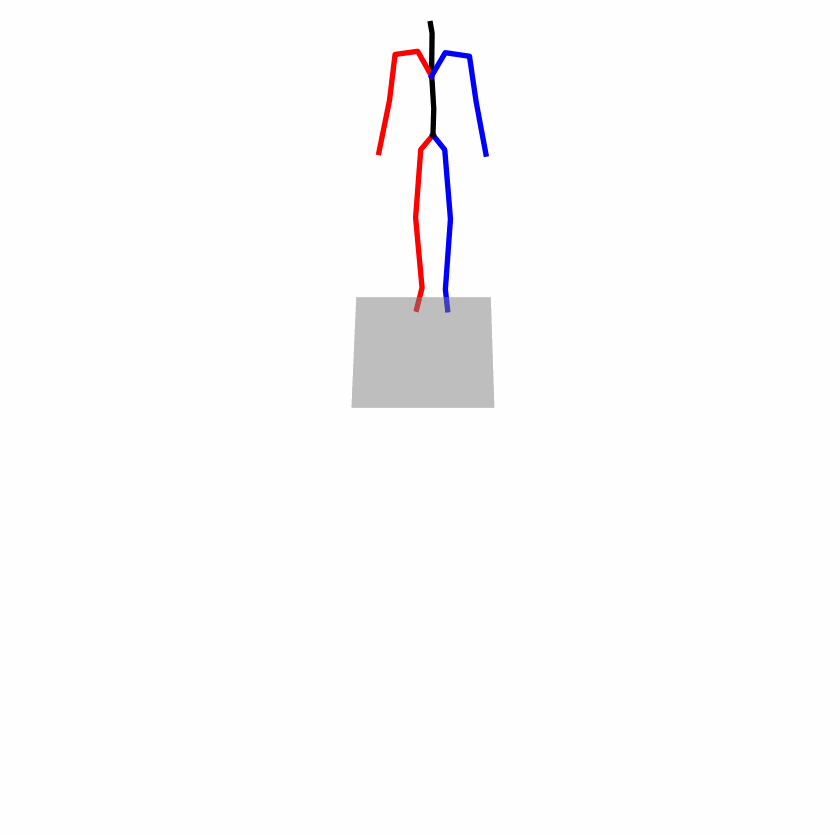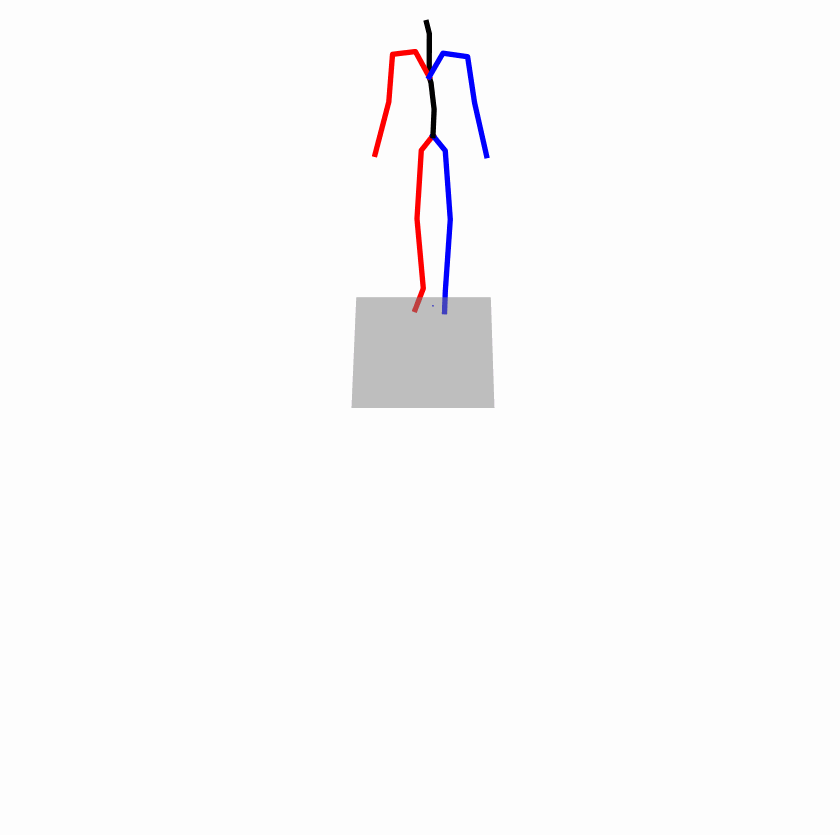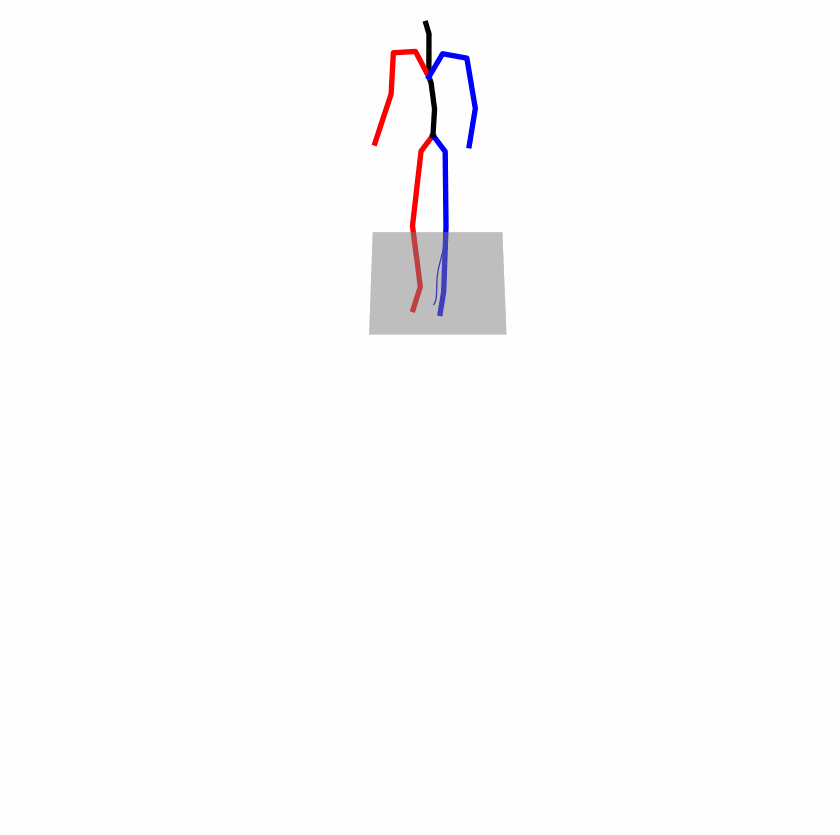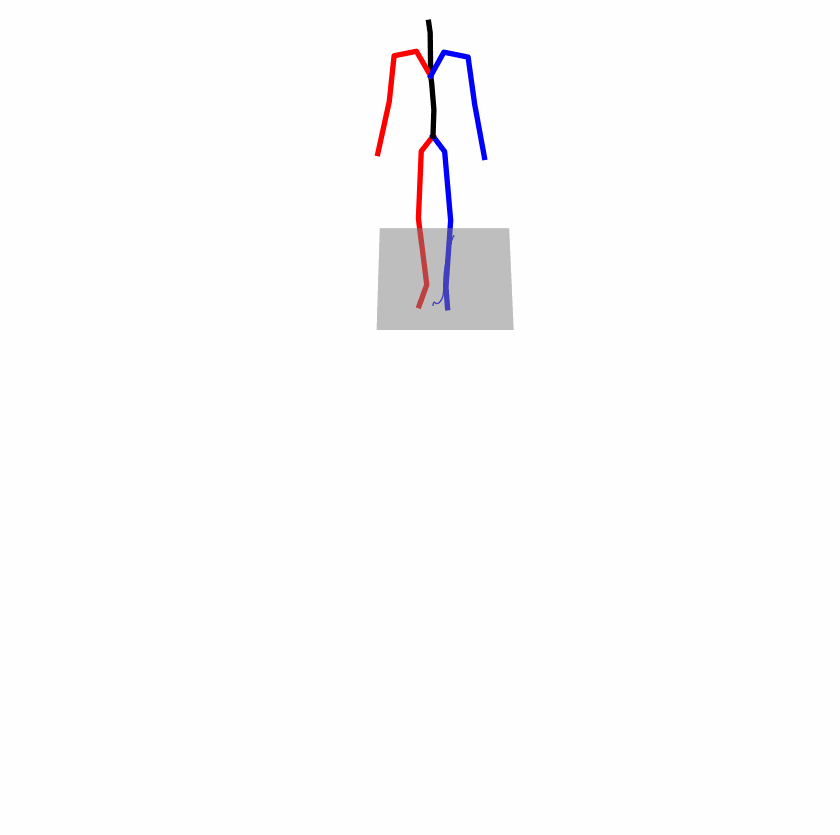
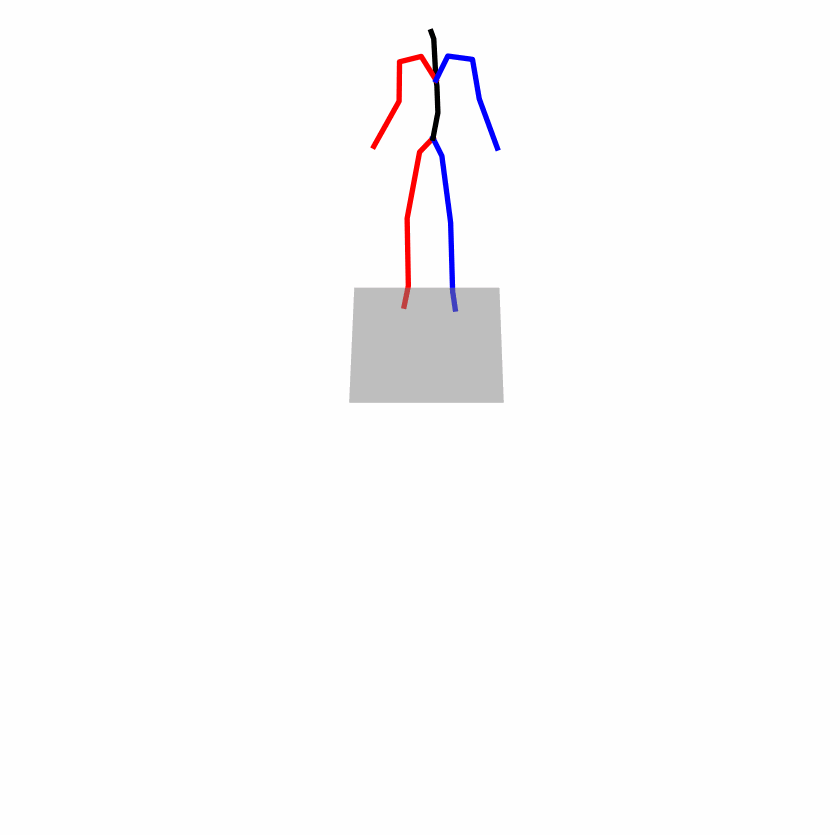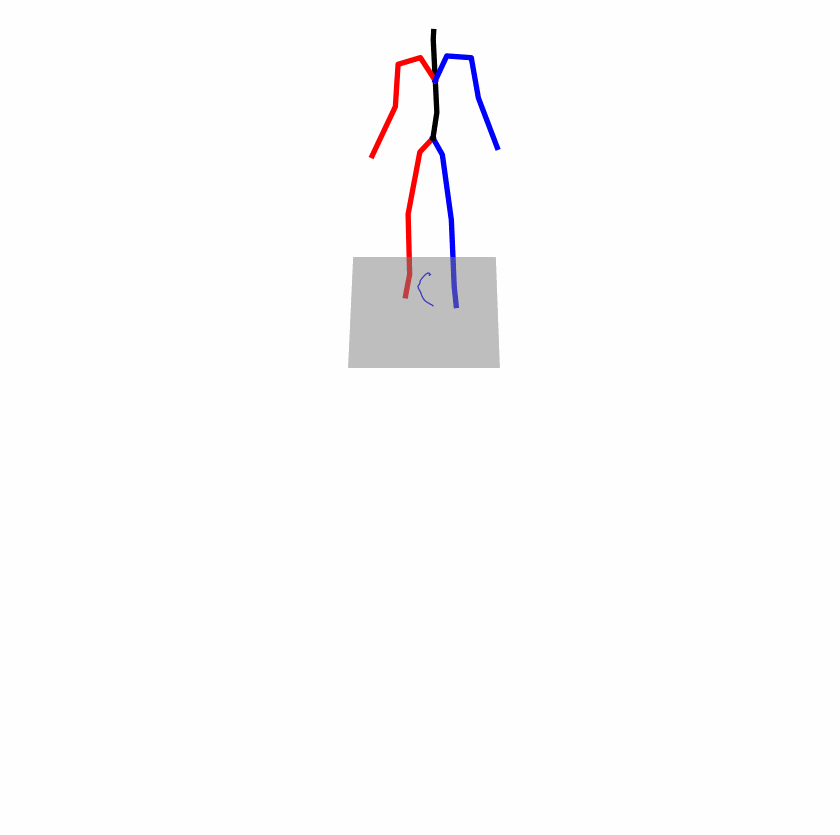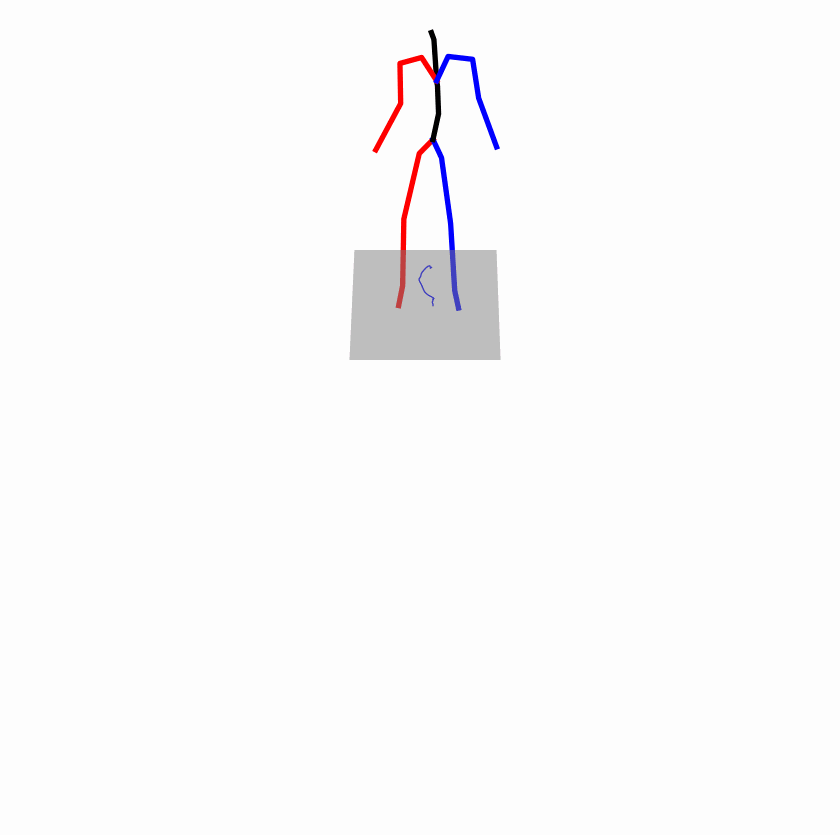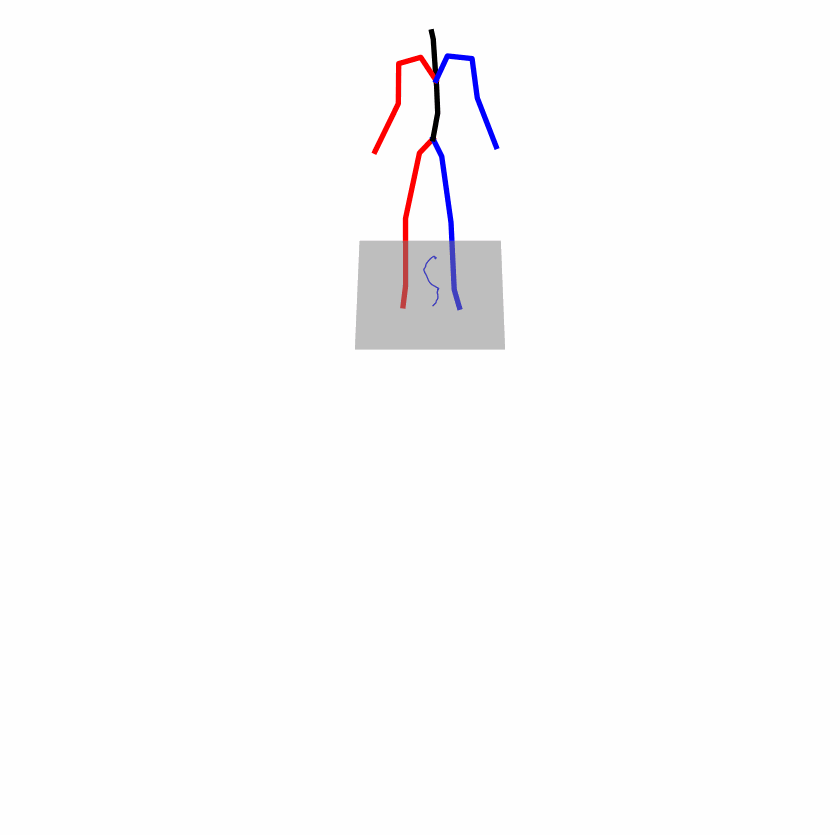
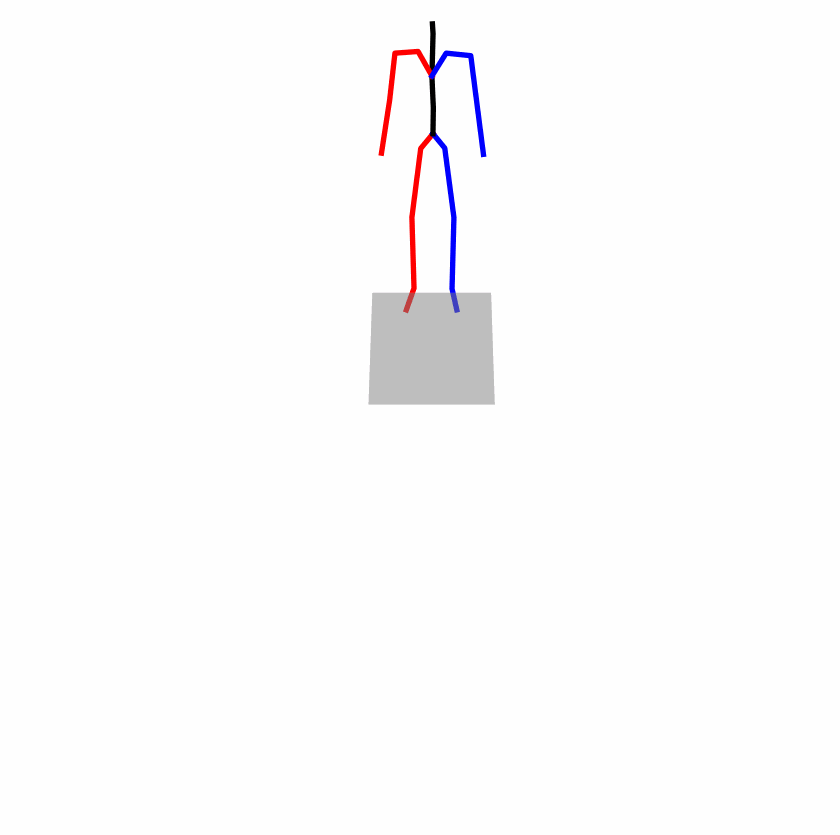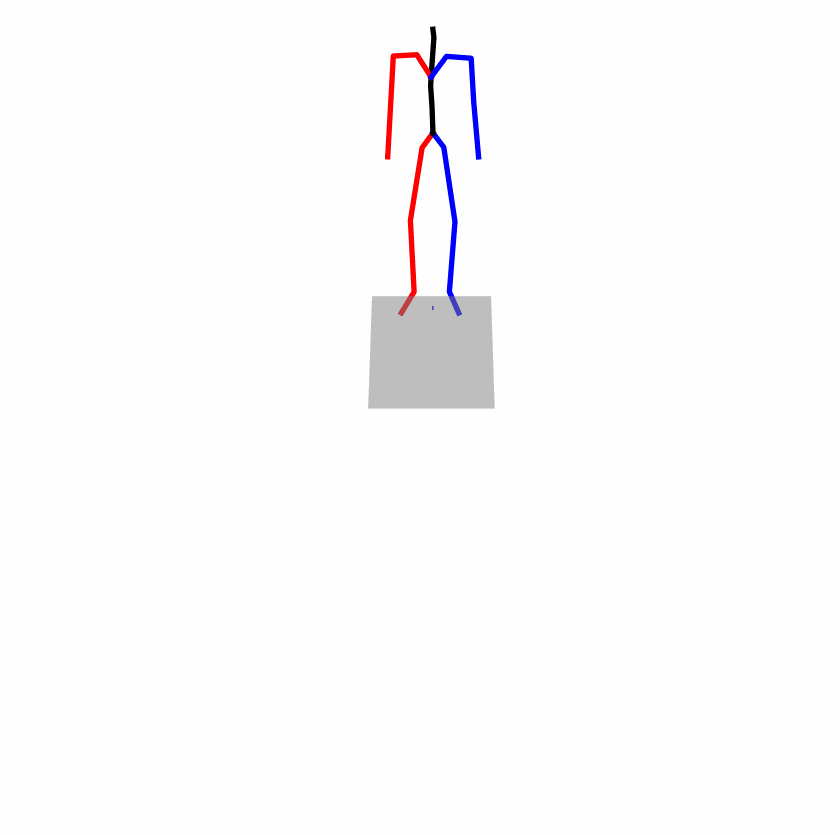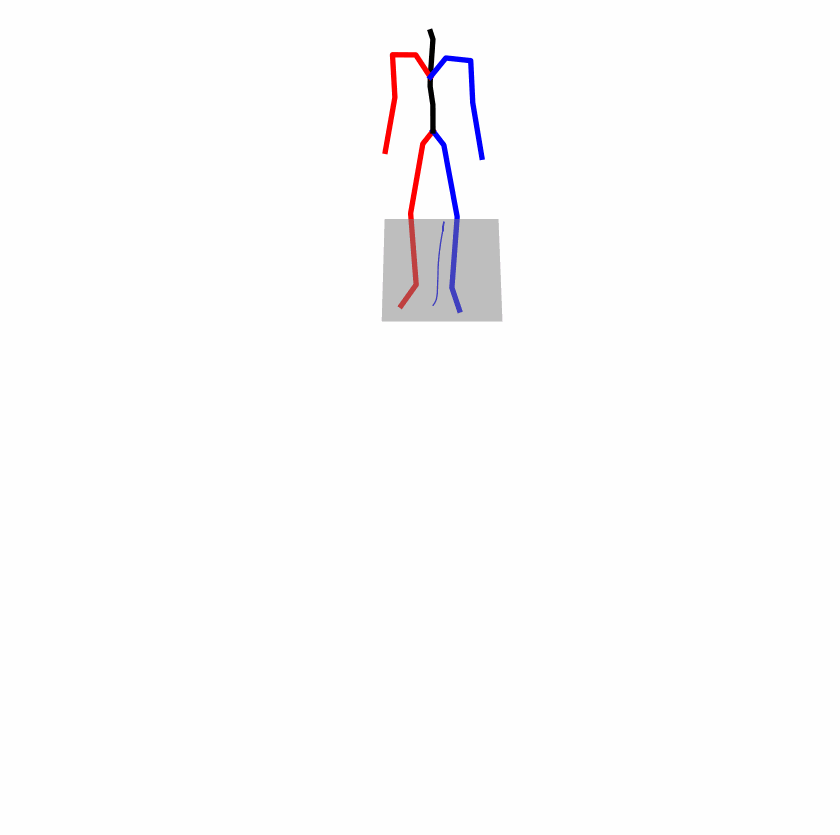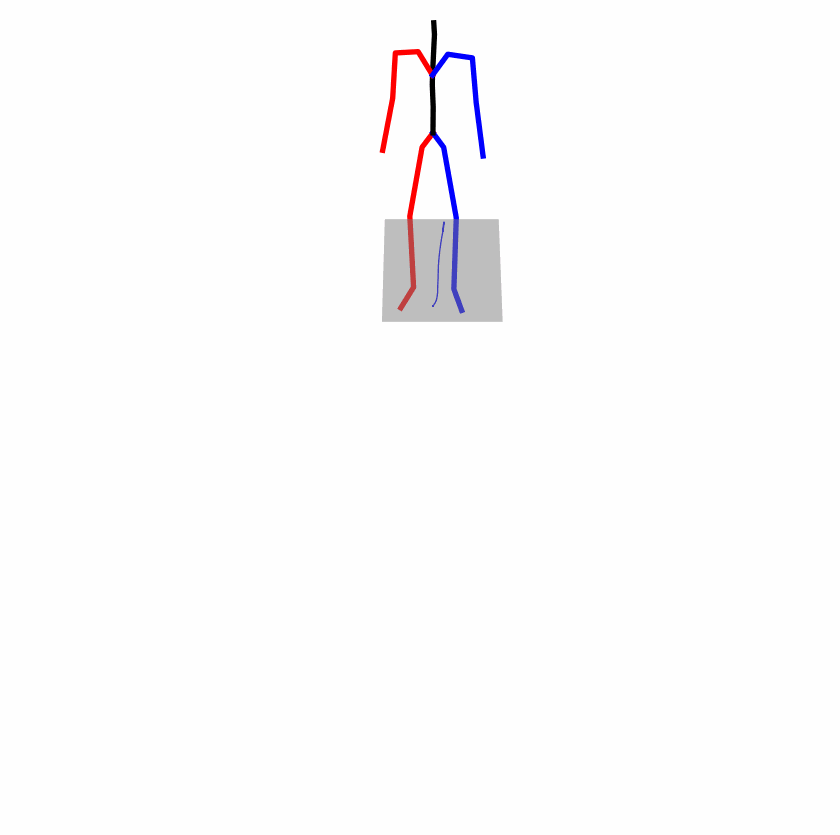
Existing Challenges

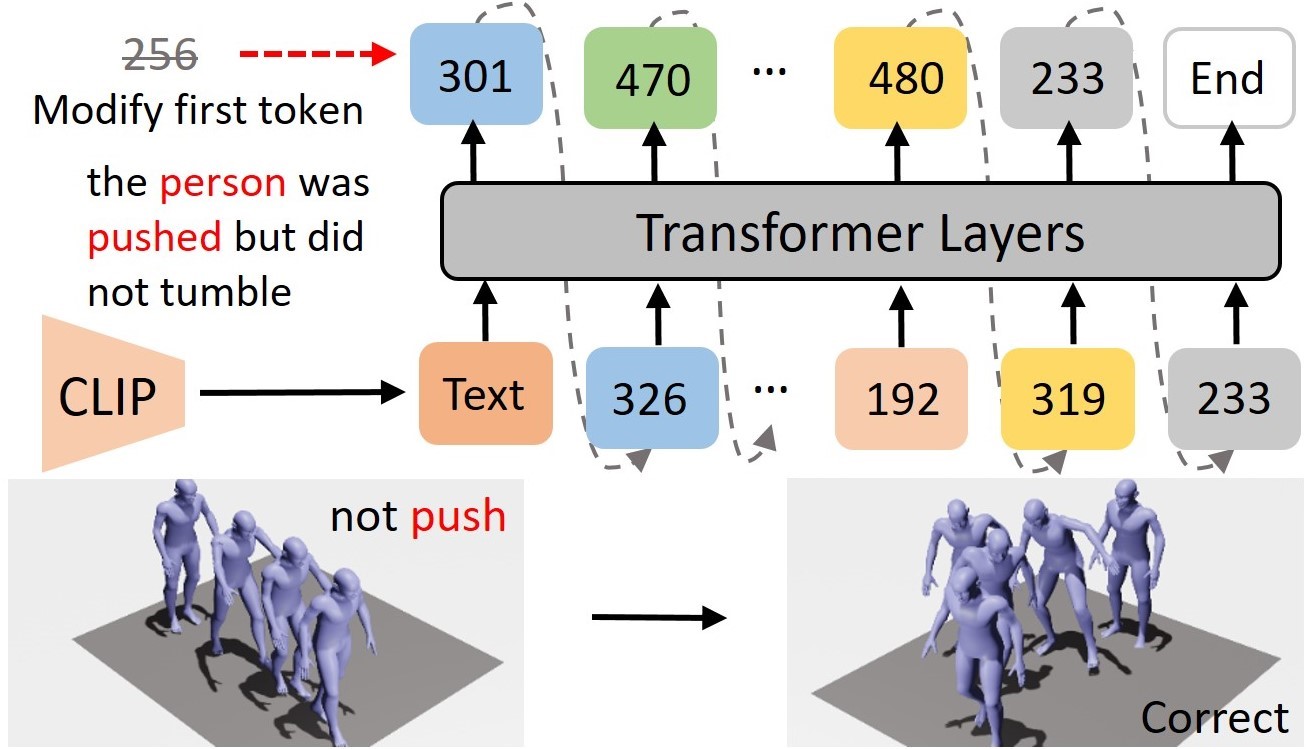
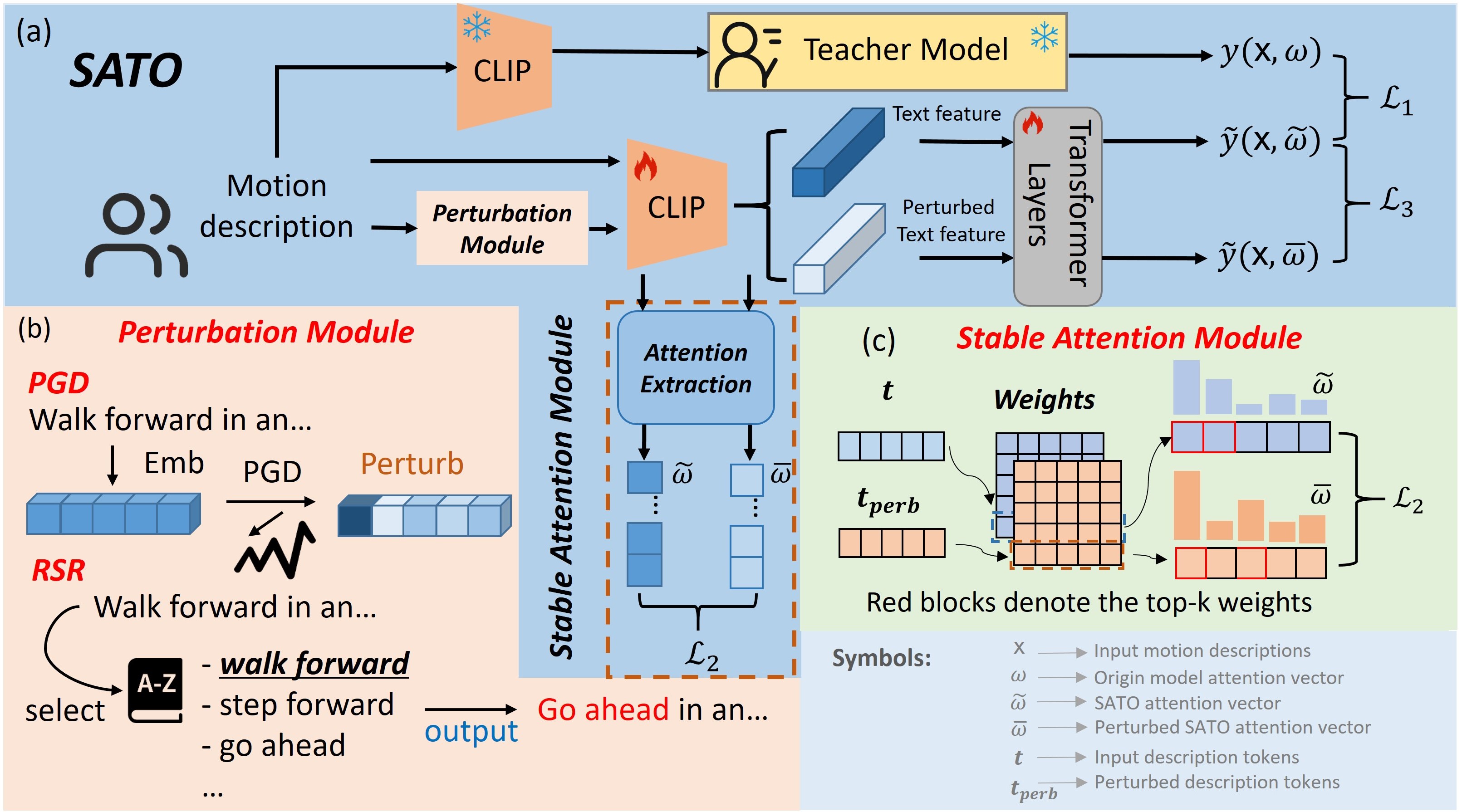
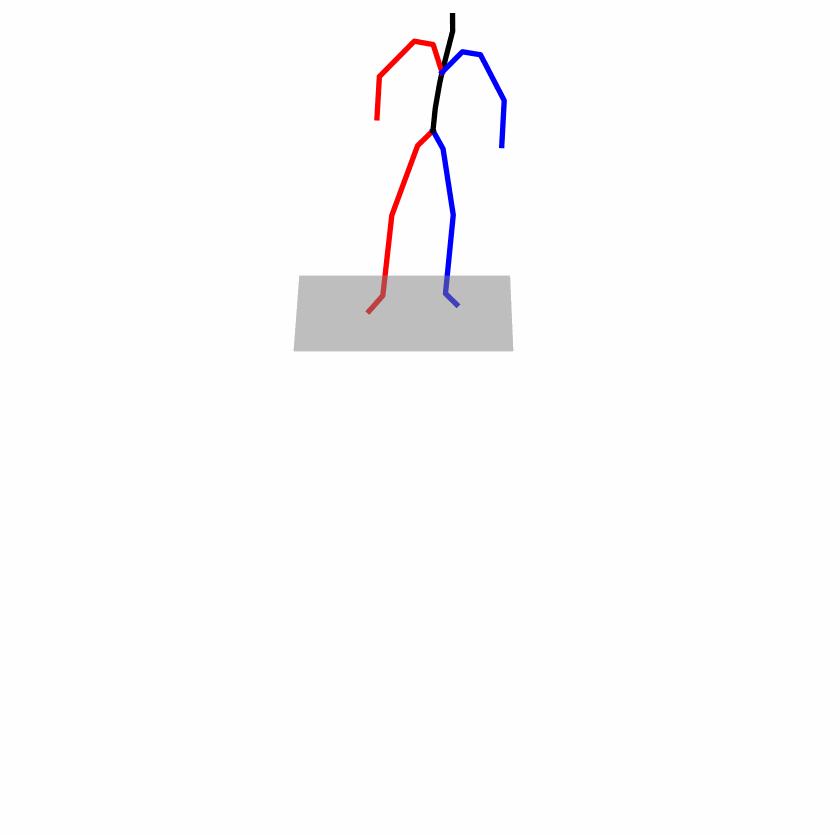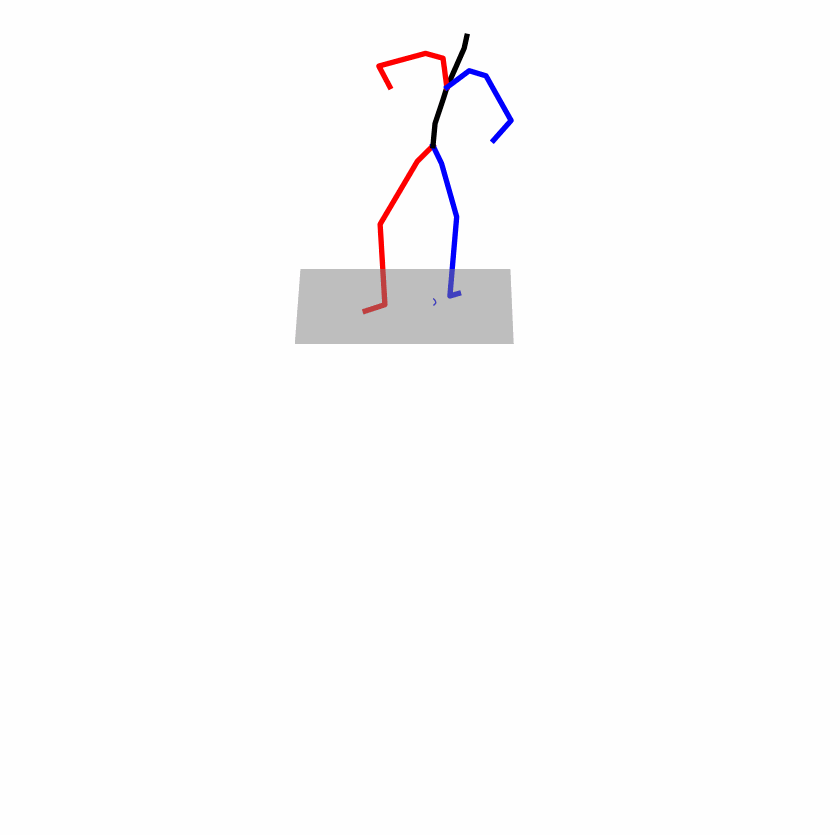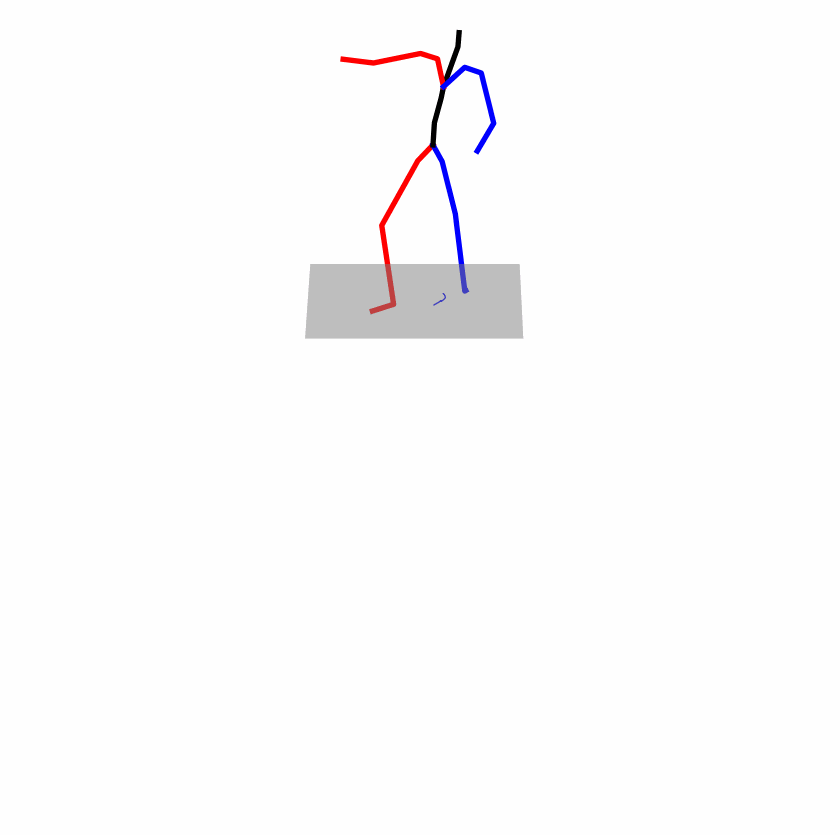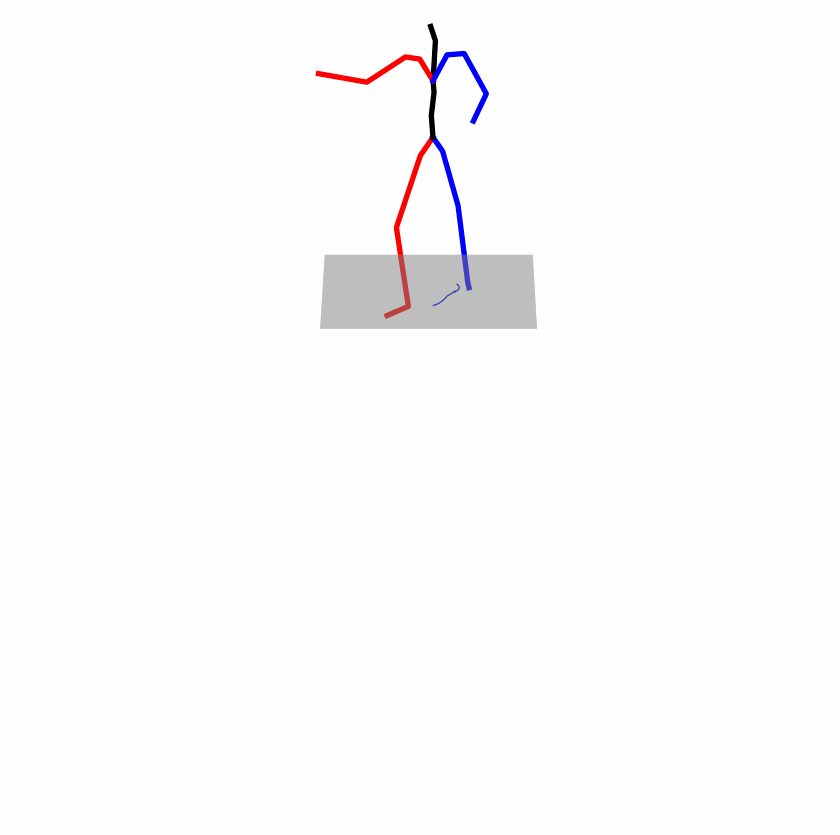
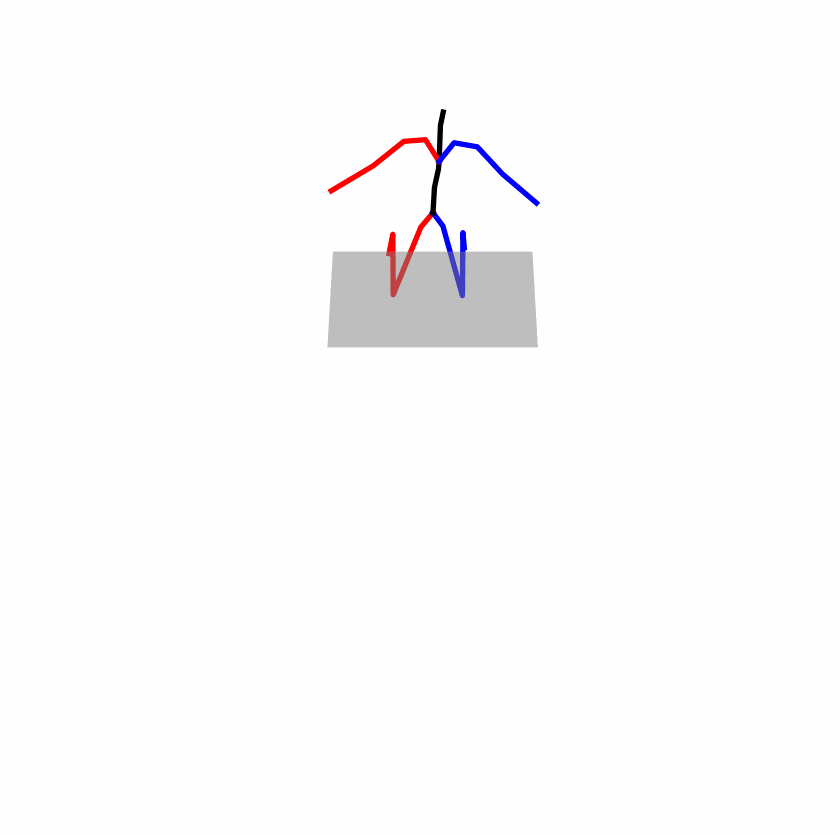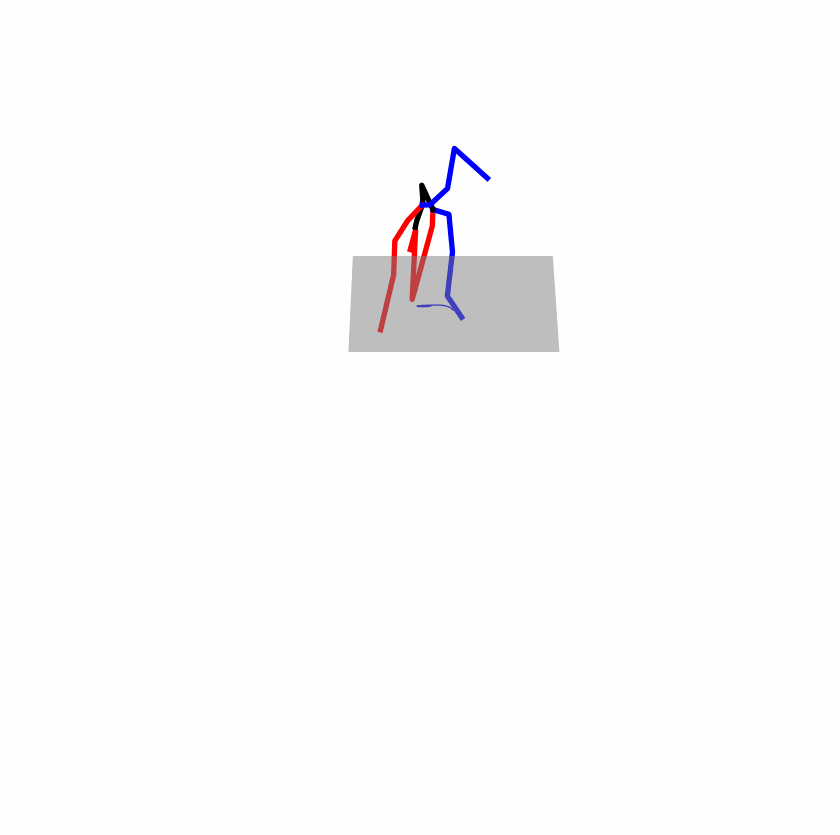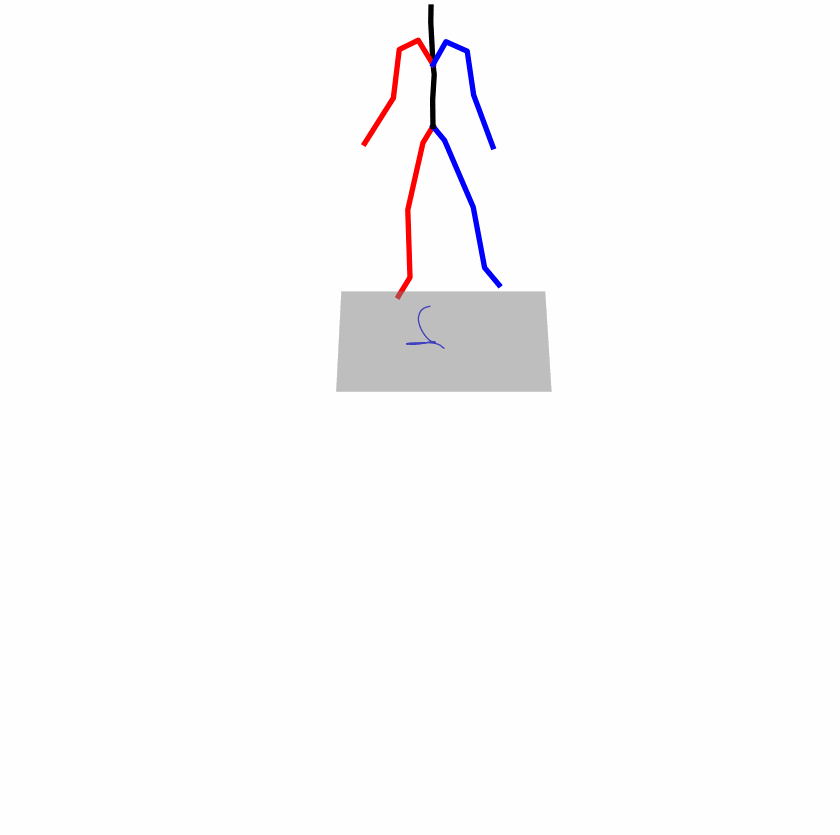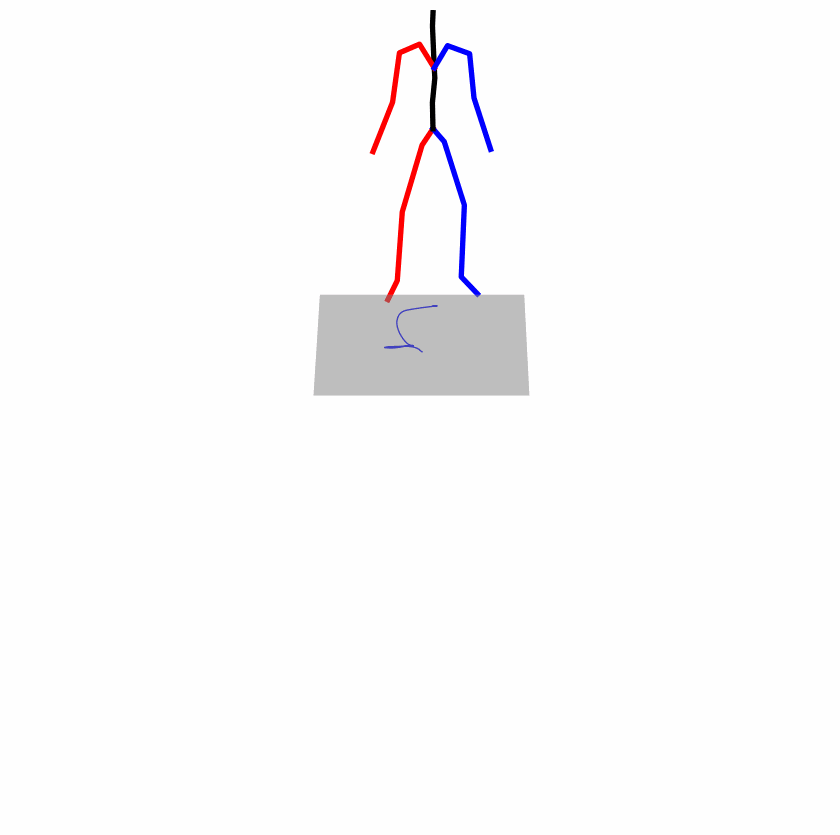
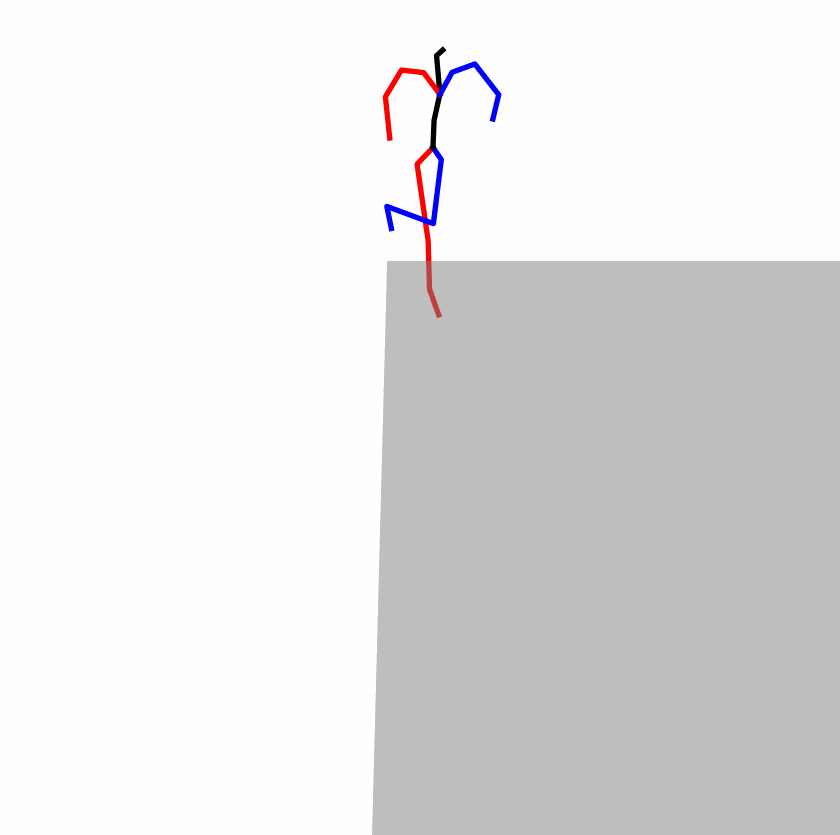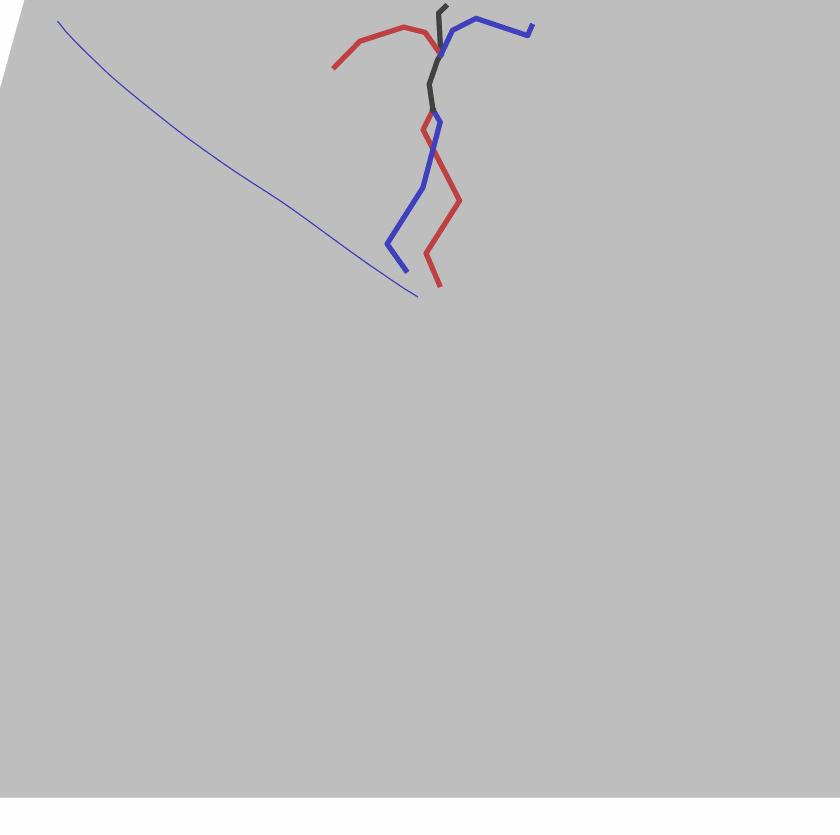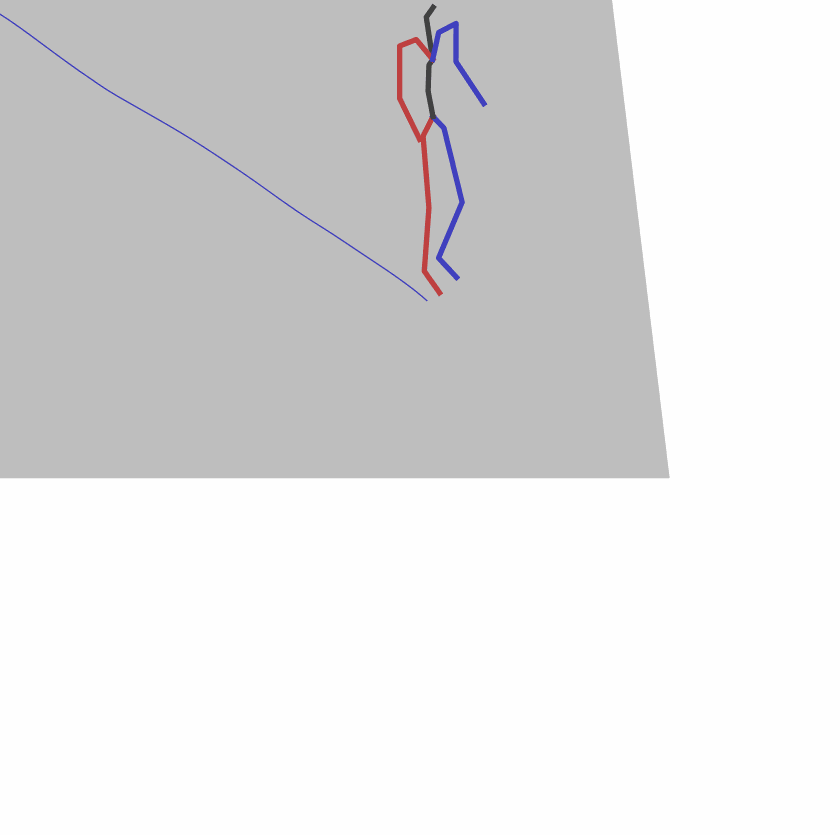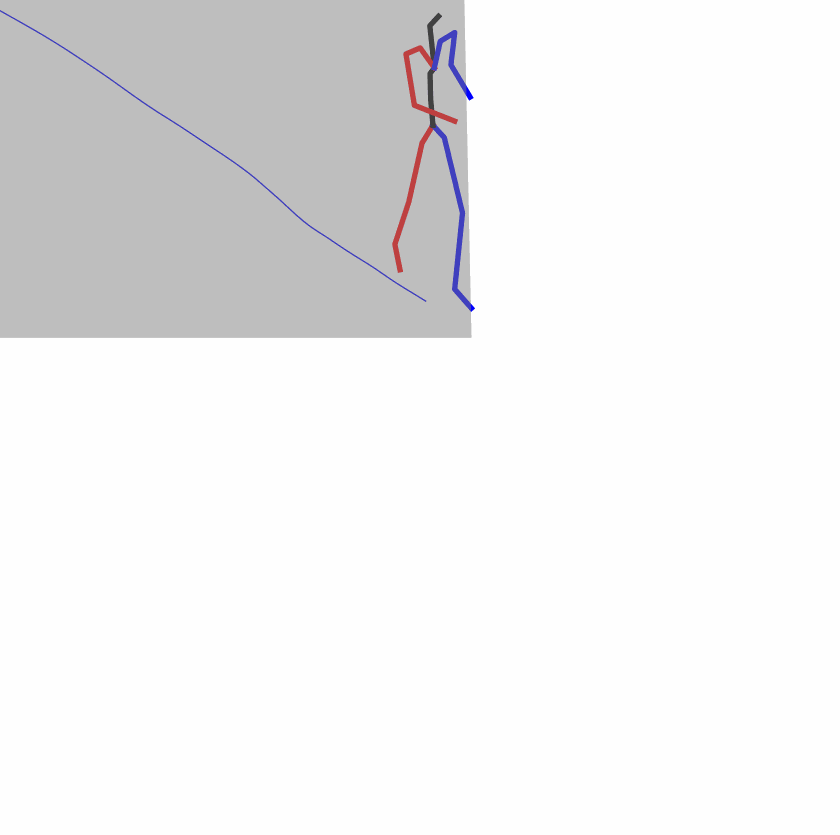
A fundamental challenge inherent in text-to-motion tasks stems from the variability of textual inputs . Even when conveying similar or the same meanings and intentions, texts can exhibit considerable variations in vocabulary and structure due to individual user preferences or linguistic nuances. Despite the considerable advancements made in these models, we find a notable weakness: all of them demonstrate instability in prediction when encountering minor textual perturbations, such as synonym substitutions. We establish a clear link between the unpredictability of model outputs and the erratic attention patterns of the text encoder module. The stability of the model manifests in the consistency of textual attention and its ability to handle perturbations in text features, highlighting its pivotal role in mitigating such errors.